
在之前的Thinking in Java之集合(容器)基础中介绍了Java容器类库的概念和基本功能,这些对于使用容器来说已经足够了。本文将更深入的探索这个类库。
在对容器有了更加完备的了解之后,本文将介绍散列机制是如何工作的,以及在使用散列容器时怎样编写hashCode()和equals()方法。还将介绍为什么某些容器会有不同版本的实现,以及怎样在它们之间进行选择。本文最后将以对通用便利的工具和特殊类的探索作为结束。
1.完整的容器分类法
下面是集合类库更加完备的图。包括抽象类和遗留构建(不包括Queue的实现):
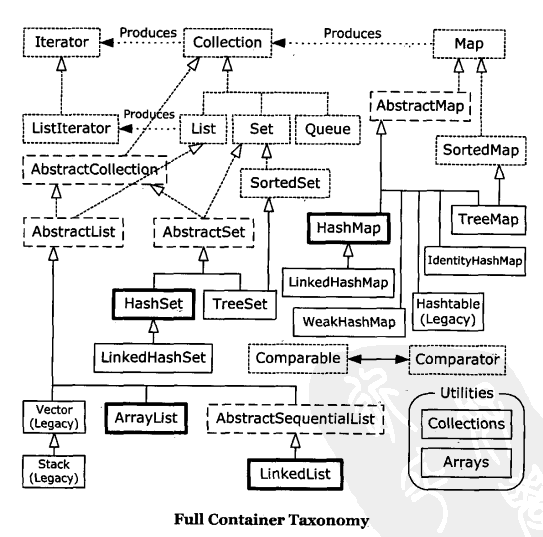
Java SE5新添加了:
- Queue接口(LinkedList已经为实现该接口做了修改)及其实现PriorityQueue和各种风格的BlockingQueue,其中BlockingQueue将在多线程中介绍。
- ConcurrentMap接口及其实现ConcurrentHashMap,它们也是用于多线程机制的。
- CopyOnWriteArrayList和CopyOnWriteArraySet,它们同样也是用于多线程机制的。
- EnumSet和EnumMap,为使用enum而设计的Set和Map的特殊实现,将在枚举中介绍。
- 在Collections类中的多个便利方法。
虚线框表示abstract类,你可以看到大量的类的名字都是以Abstract开头的。这些类可能最初看起来有点令人困惑,但是他们只是部分实现了特定接口的工具。例如,如果你在创建自己的Set,那么并不用从Set接口开始并实现其中的全部方法,只需从AbstractSet继承,然后执行一些创建新类必须的工作。但是,事实上容器类库包含足够多的功能,任何时刻都可以满足你的需求,因此你通常可以忽略以Abstract开头的这些类。
2.填充容器
虽然容器打印的问题解决了,容器的填充仍然像java.util.Arrays一样面临同样的不足。就像Arrays一样,相应的Collections类也有一些实用是static方法,其中包括fill()。与Arrays版本一样,此fill()方法也是只复制同一个对象引用来填充整个容器的,并且只对List对象有用,但是所产生的列表可以传递给构造器或addAll()方法:
package com.zjwave.thinkinjava.collection.fill;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class FillingLists {
public static void main(String[] args) {
List<StringAddress> list = new ArrayList<>(Collections.nCopies(4,new StringAddress("Hello")));
System.out.println(list);
Collections.fill(list,new StringAddress("World!"));
System.out.println(list);
}
}
class StringAddress{
private String s;
public StringAddress(String s) {
this.s = s;
}
@Override
public java.lang.String toString() {
return super.toString() + " " + s;
}
}
这个示例展示了两种用对单个对象的引用来填充Collection的方式,第一种是使用Collections.nCopies()创建传递给构造器的List,这里填充的是ArrayList。
StringAddress的toString()方法调用Object.toString()并产生该类的名字,后面紧跟对象的散列码的无符号十六进制表示(通过hashCode()生成的)。从输出中你可以看到所有引用都被设置为指向相同的对象,在第二种方法的Collections.fill()被调用之后也是如此。fill()方法的用处更有限,因为它只能替换已经在List中存在的元素,而不能添加新的元素。
2.1 一种Generator解决方案
事实上,所有的Collection子类型都有接收另一个Collection对象的构造器,用所接收的Collection对象中的元素来填充新的容器。为了更加容易地创建测试数据,我们需要做的是构件接受Generator和quantity数值并将它们作为构造器参数的类:
package com.zjwave.thinkinjava.collection;
import com.zjwave.thinkinjava.generics.Generator;
import java.util.ArrayList;
public class CollectionData<T> extends ArrayList<T> {
public CollectionData(Generator<T> gen,int quantity) {
for (int i = 0; i < quantity; i++) {
add(gen.next());
}
}
// A generic convenience method:
public static <T> CollectionData<T> list(Generator<T> gen,int quantity){
return new CollectionData<>(gen,quantity);
}
}
这个类使用GeneratorGenerator在容器中放置所需数量的对象,然后产生的容器可以传递给任何Collection的构造器,这个构造器会把其中的数据复制到自身中。addAll()方法是所有Collection子类型的一部分,它也可以用来组装现有的Collection。
泛型便利方法可以减少在使用类时所必须的类型检查数量。
CollectionData是适配器设计模式的一个实例,它将Generator适配到Collection的构造器上。
下面是初始化LinkedHashSet的一个示例:
package com.zjwave.thinkinjava.collection;
import com.zjwave.thinkinjava.generics.Generator;
import java.util.LinkedHashSet;
import java.util.Set;
public class CollectionDataTest {
public static void main(String[] args) {
Set<String> set = new LinkedHashSet<>(new CollectionData<>(new Government(), 15));
//Using the convenience method:
set.addAll(CollectionData.list(new Government(),15));
System.out.println(set);
}
}
class Government implements Generator<String> {
String[] foundation = ("strange women lying in ponds " +
"distributing swords is no basis for a system of government").split(" ");
private int index;
@Override
public String next() {
return foundation[index++];
}
}

这些元素的顺序与它们的插入顺序相同,因为LinkedHashSet维护的是保持了插入顺序的链接列表。
在之前文章:Thinking in Java——数组:RandomGenerator中定义的所有操作符现在通过CollectionData适配器都是可用的。下面是使用了其中两个操作符的示例:
package com.zjwave.thinkinjava.collection;
import com.zjwave.thinkinjava.arrays.RandomGenerator;
import java.util.ArrayList;
import java.util.HashSet;
public class CollectionDataGeneration {
public static void main(String[] args) {
System.out.println(new ArrayList<>(CollectionData.list(
//Convenience method
new RandomGenerator.String(9),10
)));
System.out.println(new HashSet<>(CollectionData.list(
new RandomGenerator.Integer(),10
)));
}
}
RandomGenerator.String所产生的String长度是通过构造器参数控制的。
2.2 Map生成器
我们可以对Map使用相同的方式,但是这需要有一个Pair类,因为为了组装Map,每次调用Generator的next()方法都必须产生一个键值对:
package com.zjwave.thinkinjava.collection;
public class Pair<K,V> {
public final K key;
public final V value;
public Pair(K key, V value) {
this.key = key;
this.value = value;
}
}
key和value域都是public和final的,这是为了使Pair成为只读的数据传输对象(或信使)。
Map适配器现在可以使用各种不同的Generator、Iterator和常量值的组合来填充其Map初始化对象:
package com.zjwave.thinkinjava.collection;
import com.zjwave.thinkinjava.generics.Generator;
import java.util.LinkedHashMap;
public class MapData<K,V> extends LinkedHashMap<K,V> {
//A single Pair Generator:
public MapData(Generator<Pair<K,V>> gen,int quantity){
for (int i = 0; i < quantity; i++) {
Pair<K, V> p = gen.next();
put(p.key,p.value);
}
}
//Two separate Generators:
public MapData(Generator<K> genK,Generator<V> genV,int quantity){
for (int i = 0; i < quantity; i++) {
put(genK.next(),genV.next());
}
}
// A key Generator and a single value:
public MapData(Generator<K> genK,V value,int quantity){
for (int i = 0; i < quantity; i++) {
put(genK.next(),value);
}
}
//An Iterable and a value Generator:
public MapData(Iterable<K> genK,Generator<V> genV){
for (K k : genK) {
put(k,genV.next());
}
}
//An Iterable and a single value:
public MapData(Iterable<K> genK,V value){
for (K k : genK) {
put(k,value);
}
}
//Generic convenience method
public static <K,V> MapData<K,V> map(Generator<Pair<K,V>> gen,int quantity){
return new MapData<>(gen,quantity);
}
public static <K,V> MapData<K,V> map(Generator<K> genK,Generator<V> genV,int quantity){
return new MapData<>(genK,genV,quantity);
}
public static <K,V> MapData<K,V> map(Generator<K> genK,V value,int quantity){
return new MapData<>(genK,value,quantity);
}
public static <K,V> MapData<K,V> map(Iterable<K> genK,Generator<V> genV){
return new MapData<>(genK,genV);
}
public static <K,V> MapData<K,V> map(Iterable<K> genK,V value){
return new MapData<>(genK,value);
}
}
这给了你一个机会,去选择使用单一的Generator<Pair<K,V>>、两个分离的Generator、一个Generator和一个常量值,一个Iterable(包括任何Collection)和一个Generator,还是一个Iterable和一个单一值。泛型便利方法可以减少在创建MapData类时所必须的类型检查数量。
下面是一个使用MapData的示例。LettersGenerator产生一个Iterator还实现了Iterable,通过这种方式,它可以被用来测试MapData.map()方法,而这些方法都需要用到Iterable:
package com.zjwave.thinkinjava.collection;
import com.zjwave.thinkinjava.arrays.CountingGenerator;
import com.zjwave.thinkinjava.arrays.RandomGenerator;
import com.zjwave.thinkinjava.generics.Generator;
import java.util.Iterator;
public class MapDataTest {
public static void main(String[] args) {
// Pair Generator:
System.out.println(MapData.map(new Letters(), 11));
// Two separate generators :
System.out.println(MapData.map(new CountingGenerator.Character(), new RandomGenerator.String(3), 8));
// A key Generator and a single value
System.out.println(MapData.map(new CountingGenerator.Character(),"Value",6));
// An Iterable and a value Generator:
System.out.println(MapData.map(new Letters(),new RandomGenerator.String(3)));
// An Iterable and a single value:
System.out.println(MapData.map(new Letters(),"Pop"));
}
}
class Letters implements Generator<Pair<Integer, String>>, Iterable<Integer> {
private int size = 9;
private int number = 1;
private char letter = 'A';
@Override
public Pair<Integer, String> next() {
return new Pair<>(number++, "" + letter++);
}
@Override
public Iterator<Integer> iterator() {
return new Iterator<Integer>() {
@Override
public boolean hasNext() {
return number < size;
}
@Override
public Integer next() {
return number++;
}
};
}
}这个示例也使用了Thinking in Java——数组:CountingGenerator中的生成器。
可以使用工具来创建任何用于Map或Collection的生成数据集,然后通过构造器或Map.putAll()和Collection.addAll()方法来初始化Map和Collection。
2.3 使用Abstract类
对于产生用于容器的测试数据问题,另一种解决方式是创建定制的Collection和Map实现。每个java.util容器都有其自己的Abstract类,它们提供了该容器的部分实现,因此你必须做的只是去实现那些产生想要的容器所必须的方法。如果所产生的容器是只读的,就像通常用的测试数据那样,那么你需要提供的方法数量将减少到最少。
尽管在本例中不是特别需要,但是下面的解决方案还是提供了一个机会来演示另一种设计模式:享元。你可以在普通的解决方案需要过多的对象,或者产生普通对象太占用空间时使用享元。享元模式使得对象的一部分可以被具体化,因此,与对象中的所有事物都包含在对象内部不同,我们可以在更加高效的外部表中查找对象的一部分或整体(或者通过某些其他节省空间的计算来产生对象的一部分或整体)。
这个示例的关键之处在于演示通过集成java.uti.Abstract来创建定制的Map和Collection到底有多简单。为了创建只读Map,可以继承AbstractMap并实现entrySet()。为了创建只读的Set,可以继承AbstractSet并实现iterator()和size()。
本例中使用的数据集是由世界上的国家以及它们的首都构成的Map。capitals()方法产生国家与首都的Map,names()方法产生国名的List。在两种情况中,你都可以通过提供表所需尺寸的int参数来获取部分列表:
package com.zjwave.thinkinjava.collection;
import java.util.*;
public class Countries {
public static final String[][] DATA = {
// Africa
{
"ALGERIA", "Algiers"
}, {
"ANGOLA", "Luanda"
},
{
"BENIN", "Porto-Novo"
}, {
"BOTSWANA", "Gaberone"
},
{
"BULGARIA", "Sofia"
}, {
"BURKINA FASO", "Ouagadougou"
},
{
"BURUNDI", "Bujumbura"
},
{
"CAMEROON", "Yaounde"
}, {
"CAPE VERDE", "Praia"
},
{
"CENTRAL AFRICAN REPUBLIC", "Bangui"
},
{
"CHAD", "N'djamena"
}, {
"COMOROS", "Moroni"
},
{
"CONGO", "Brazzaville"
}, {
"DJIBOUTI", "Dijibouti"
},
{
"EGYPT", "Cairo"
}, {
"EQUATORIAL GUINEA", "Malabo"
},
{
"ERITREA", "Asmara"
}, {
"ETHIOPIA", "Addis Ababa"
},
{
"GABON", "Libreville"
}, {
"THE GAMBIA", "Banjul"
},
{
"GHANA", "Accra"
}, {
"GUINEA", "Conakry"
},
{
"BISSAU", "Bissau"
},
{
"COTE D'IVOIR (IVORY COAST)", "Yamoussoukro"
},
{
"KENYA", "Nairobi"
}, {
"LESOTHO", "Maseru"
},
{
"LIBERIA", "Monrovia"
}, {
"LIBYA", "Tripoli"
},
{
"MADAGASCAR", "Antananarivo"
}, {
"MALAWI", "Lilongwe"
},
{
"MALI", "Bamako"
}, {
"MAURITANIA", "Nouakchott"
},
{
"MAURITIUS", "Port Louis"
}, {
"MOROCCO", "Rabat"
},
{
"MOZAMBIQUE", "Maputo"
}, {
"NAMIBIA", "Windhoek"
},
{
"NIGER", "Niamey"
}, {
"NIGERIA", "Abuja"
},
{
"RWANDA", "Kigali"
},
{
"SAO TOME E PRINCIPE", "Sao Tome"
},
{
"SENEGAL", "Dakar"
}, {
"SEYCHELLES", "Victoria"
},
{
"SIERRA LEONE", "Freetown"
}, {
"SOMALIA", "Mogadishu"
},
{
"SOUTH AFRICA", "Pretoria/Cape Town"
},
{
"SUDAN", "Khartoum"
},
{
"SWAZILAND", "Mbabane"
}, {
"TANZANIA", "Dodoma"
},
{
"TOGO", "Lome"
}, {
"TUNISIA", "Tunis"
},
{
"UGANDA", "Kampala"
},
{
"DEMOCRATIC REPUBLIC OF THE CONGO (ZAIRE)",
"Kinshasa"
},
{
"ZAMBIA", "Lusaka"
}, {
"ZIMBABWE", "Harare"
},
// Asia
{
"AFGHANISTAN", "Kabul"
}, {
"BAHRAIN", "Manama"
},
{
"BANGLADESH", "Dhaka"
}, {
"BHUTAN", "Thimphu"
},
{
"BRUNEI", "Bandar Seri Begawan"
},
{
"CAMBODIA", "Phnom Penh"
},
{
"CHINA", "Beijing"
}, {
"CYPRUS", "Nicosia"
},
{
"INDIA", "New Delhi"
}, {
"INDONESIA", "Jakarta"
},
{
"IRAN", "Tehran"
}, {
"IRAQ", "Baghdad"
},
{
"ISRAEL", "Jerusalem"
}, {
"JAPAN", "Tokyo"
},
{
"JORDAN", "Amman"
}, {
"KUWAIT", "Kuwait City"
},
{
"LAOS", "Vientiane"
}, {
"LEBANON", "Beirut"
},
{
"MALAYSIA", "Kuala Lumpur"
}, {
"THE MALDIVES", "Male"
},
{
"MONGOLIA", "Ulan Bator"
},
{
"MYANMAR (BURMA)", "Rangoon"
},
{
"NEPAL", "Katmandu"
}, {
"NORTH KOREA", "P'yongyang"
},
{
"OMAN", "Muscat"
}, {
"PAKISTAN", "Islamabad"
},
{
"PHILIPPINES", "Manila"
}, {
"QATAR", "Doha"
},
{
"SAUDI ARABIA", "Riyadh"
}, {
"SINGAPORE", "Singapore"
},
{
"SOUTH KOREA", "Seoul"
}, {
"SRI LANKA", "Colombo"
},
{
"SYRIA", "Damascus"
},
{
"TAIWAN (REPUBLIC OF CHINA)", "Taipei"
},
{
"THAILAND", "Bangkok"
}, {
"TURKEY", "Ankara"
},
{
"UNITED ARAB EMIRATES", "Abu Dhabi"
},
{
"VIETNAM", "Hanoi"
}, {
"YEMEN", "Sana'a"
},
// Australia and Oceania
{
"AUSTRALIA", "Canberra"
}, {
"FIJI", "Suva"
},
{
"KIRIBATI", "Bairiki"
},
{
"MARSHALL ISLANDS", "Dalap-Uliga-Darrit"
},
{
"MICRONESIA", "Palikir"
}, {
"NAURU", "Yaren"
},
{
"NEW ZEALAND", "Wellington"
}, {
"PALAU", "Koror"
},
{
"PAPUA NEW GUINEA", "Port Moresby"
},
{
"SOLOMON ISLANDS", "Honaira"
}, {
"TONGA", "Nuku'alofa"
},
{
"TUVALU", "Fongafale"
}, {
"VANUATU", "< Port-Vila"
},
{
"WESTERN SAMOA", "Apia"
},
// Eastern Europe and former USSR
{
"ARMENIA", "Yerevan"
}, {
"AZERBAIJAN", "Baku"
},
{
"BELARUS (BYELORUSSIA)", "Minsk"
},
{
"GEORGIA", "Tbilisi"
},
{
"KAZAKSTAN", "Almaty"
}, {
"KYRGYZSTAN", "Alma-Ata"
},
{
"MOLDOVA", "Chisinau"
}, {
"RUSSIA", "Moscow"
},
{
"TAJIKISTAN", "Dushanbe"
}, {
"TURKMENISTAN", "Ashkabad"
},
{
"UKRAINE", "Kyiv"
}, {
"UZBEKISTAN", "Tashkent"
},
// Europe
{
"ALBANIA", "Tirana"
}, {
"ANDORRA", "Andorra la Vella"
},
{
"AUSTRIA", "Vienna"
}, {
"BELGIUM", "Brussels"
},
{
"BOSNIA", "-"
}, {
"HERZEGOVINA", "Sarajevo"
},
{
"CROATIA", "Zagreb"
}, {
"CZECH REPUBLIC", "Prague"
},
{
"DENMARK", "Copenhagen"
}, {
"ESTONIA", "Tallinn"
},
{
"FINLAND", "Helsinki"
}, {
"FRANCE", "Paris"
},
{
"GERMANY", "Berlin"
}, {
"GREECE", "Athens"
},
{
"HUNGARY", "Budapest"
}, {
"ICELAND", "Reykjavik"
},
{
"IRELAND", "Dublin"
}, {
"ITALY", "Rome"
},
{
"LATVIA", "Riga"
}, {
"LIECHTENSTEIN", "Vaduz"
},
{
"LITHUANIA", "Vilnius"
}, {
"LUXEMBOURG", "Luxembourg"
},
{
"MACEDONIA", "Skopje"
}, {
"MALTA", "Valletta"
},
{
"MONACO", "Monaco"
}, {
"MONTENEGRO", "Podgorica"
},
{
"THE NETHERLANDS", "Amsterdam"
}, {
"NORWAY", "Oslo"
},
{
"POLAND", "Warsaw"
}, {
"PORTUGAL", "Lisbon"
},
{
"ROMANIA", "Bucharest"
}, {
"SAN MARINO", "San Marino"
},
{
"SERBIA", "Belgrade"
}, {
"SLOVAKIA", "Bratislava"
},
{
"SLOVENIA", "Ljuijana"
}, {
"SPAIN", "Madrid"
},
{
"SWEDEN", "Stockholm"
}, {
"SWITZERLAND", "Berne"
},
{
"UNITED KINGDOM", "London"
}, {
"VATICAN CITY", "---"
},
// North and Central America
{
"ANTIGUA AND BARBUDA", "Saint John's"
},
{
"BAHAMAS", "Nassau"
},
{
"BARBADOS", "Bridgetown"
}, {
"BELIZE", "Belmopan"
},
{
"CANADA", "Ottawa"
}, {
"COSTA RICA", "San Jose"
},
{
"CUBA", "Havana"
}, {
"DOMINICA", "Roseau"
},
{
"DOMINICAN REPUBLIC", "Santo Domingo"
},
{
"EL SALVADOR", "San Salvador"
},
{
"GRENADA", "Saint George's"
},
{
"GUATEMALA", "Guatemala City"
},
{
"HAITI", "Port-au-Prince"
},
{
"HONDURAS", "Tegucigalpa"
}, {
"JAMAICA", "Kingston"
},
{
"MEXICO", "Mexico City"
}, {
"NICARAGUA", "Managua"
},
{
"PANAMA", "Panama City"
}, {
"ST. KITTS", "-"
},
{
"NEVIS", "Basseterre"
}, {
"ST. LUCIA", "Castries"
},
{
"ST. VINCENT AND THE GRENADINES", "Kingstown"
},
{
"UNITED STATES OF AMERICA", "Washington, D.C."
},
// South America
{
"ARGENTINA", "Buenos Aires"
},
{
"BOLIVIA", "Sucre (legal)/La Paz(administrative)"
},
{
"BRAZIL", "Brasilia"
}, {
"CHILE", "Santiago"
},
{
"COLOMBIA", "Bogota"
}, {
"ECUADOR", "Quito"
},
{
"GUYANA", "Georgetown"
}, {
"PARAGUAY", "Asuncion"
},
{
"PERU", "Lima"
}, {
"SURINAME", "Paramaribo"
},
{
"TRINIDAD AND TOBAGO", "Port of Spain"
},
{
"URUGUAY", "Montevideo"
}, {
"VENEZUELA", "Caracas"
}};
// Use AbstractMap by implementing entrySet()
private static class FlyweightMap extends AbstractMap<String,String>{
private static class Entry implements Map.Entry<String,String>{
int index;
public Entry(int index) {
this.index = index;
}
@Override
public String getKey() {
return DATA[index][0];
}
@Override
public String getValue() {
return DATA[index][1];
}
@Override
public String setValue(String value) {
throw new UnsupportedOperationException();
}
@Override
public boolean equals(Object obj) {
return DATA[index][0].equals(obj);
}
@Override
public int hashCode() {
return DATA[index][0].hashCode();
}
}
//Use AbstractSet by implementing size() & iterator()
static class EntrySet extends AbstractSet<Map.Entry<String,String>>{
private int size;
public EntrySet(int size) {
if(size < 0){
this.size = 0;
}else if(size > DATA.length){
this.size = DATA.length;
}else{
this.size = size;
}
}
@Override
public Iterator<Map.Entry<String, String>> iterator() {
return new Iter();
}
@Override
public int size() {
return size;
}
private class Iter implements Iterator<Map.Entry<String,String>>{
//Only one Entry object per Iterator
private Entry entry = new Entry(-1);
@Override
public boolean hasNext() {
return entry.index < size - 1;
}
@Override
public Map.Entry<String, String> next() {
entry.index++;
return entry;
}
}
}
private static Set<Map.Entry<String,String>> entries = new EntrySet(DATA.length);
@Override
public Set<Map.Entry<String, String>> entrySet() {
return entries;
}
//Create a partial map of 'size' countries
static Map<String,String> select(final int size){
return new FlyweightMap(){
@Override
public Set<Map.Entry<String, String>> entrySet() {
return new EntrySet(size);
}
};
}
static Map<String,String> map = new FlyweightMap();
public static Map<String,String> capitals(){
return map;//The entire map
}
public static Map<String,String> capitals(int size){
return select(size);//A partial map
}
static List<String> names = new ArrayList<>(map.keySet());
// All the names:
public static List<String> names(){
return names;
}
// A partial list:
public static List<String> names(int size){
return new ArrayList<>(select(size).keySet());
}
public static void main(String[] args) {
System.out.println(capitals(10));
System.out.println(names(10));
System.out.println(new HashMap<>(capitals(3)));
System.out.println(new LinkedHashMap<>(capitals(3)));
System.out.println(new TreeMap<>(capitals(3)));
System.out.println(new Hashtable<>(capitals(3)));
System.out.println(new HashSet<>(names(6)));
System.out.println(new LinkedHashSet<>(names(6)));
System.out.println(new TreeSet<>(names(6)));
System.out.println(new ArrayList<>(names(6)));
System.out.println(new LinkedList<>(names(6)));
System.out.println(capitals().get("CHINA"));
}
}
//Create a partial map of 'size' countries
static Map<String,String> select(final int size){
return new FlyweightMap(){
@Override
public Set<Map.Entry<String, String>> entrySet() {
return new EntrySet(size);
}
};
}
static Map<String,String> map = new FlyweightMap();
public static Map<String,String> capitals(){
return map;//The entire map
}
public static Map<String,String> capitals(int size){
return select(size);//A partial map
}
static List<String> names = new ArrayList<>(map.keySet());
// All the names:
public static List<String> names(){
return names;
}
// A partial list:
public static List<String> names(int size){
return new ArrayList<>(select(size).keySet());
}
public static void main(String[] args) {
System.out.println(capitals(10));
System.out.println(names(10));
System.out.println(new HashMap<>(capitals(3)));
System.out.println(new LinkedHashMap<>(capitals(3)));
System.out.println(new TreeMap<>(capitals(3)));
System.out.println(new Hashtable<>(capitals(3)));
System.out.println(new HashSet<>(names(6)));
System.out.println(new LinkedHashSet<>(names(6)));
System.out.println(new TreeSet<>(names(6)));
System.out.println(new ArrayList<>(names(6)));
System.out.println(new LinkedList<>(names(6)));
System.out.println(capitals().get("CHINA"));
}
}

二维数组String[][] DATA是public的,因此它可以在其他地方使用。FlyweightMap必须实现entrySet()方法,它需要定制的Set实现和定制的Map.Entry类。这里正是享元部分:每个Map.Entry对象都只存储了它的索引,而不是实际的键和值。当你调用getKey()和getValue()时,它们会使用该索引来返回恰当的DATA元素。EntrySet可以确保它的size不会大于DATA。
你可以在EntrySet.Iterator中看到享元其他部分实现。与为DATA中的每个数据对都创建Map.Entry对象不同,每个迭代器只有一个Map.Entry。Entry对象被用作数据的视窗,它只包含在静态字符串数组中的索引。你每次调用迭代器的next()方法时,Entry中的index都会递增,使其指向下一个元素对,然后从next()返回该Iterator所持有的单一的Entry对象。
select()方法将产生一个包含指定尺寸的EntrySet的FlyweightMap,它会被用于重载过的capitals()和names()方法,正如在main()中所演示的那样。
对于某些测试,Countries的尺寸受限会成为问题。我们可以采用与产生定制容器相同的方式来解决,其中定制容器是经过初始化的,并且具有任意尺寸的数据集。下面的类是一个List,它可以具有任意尺寸,并且用Integer数据(有效地)进行了与初始化:
package com.zjwave.thinkinjava.collection;
import java.util.AbstractList;
public class CountingIntegerList extends AbstractList<Integer> {
private int size;
public CountingIntegerList(int size) {
this.size = size < 0 ? 0 : size;
}
@Override
public Integer get(int index) {
return Integer.valueOf(index);
}
@Override
public int size() {
return size;
}
public static void main(String[] args) {
System.out.println(new CountingIntegerList(30));
}
}

为了从AbstractList创建只读的List,你必须实现get()和size()。这里再次使用了享元解决方案:当你寻找值时,get()将产生它,因此这个List实际上并不比组装。
下面是包含经过预初始化,并且都是唯一的Integer和String对的Map,它可以具有任意尺寸:
package com.zjwave.thinkinjava.collection;
import java.util.AbstractMap;
import java.util.LinkedHashSet;
import java.util.Map;
import java.util.Set;
public class CountingMapData extends AbstractMap<Integer,String> {
private int size;
private static String[] chars = "A B C D E F G H I J K L M N O P Q R S T U V W X Y Z".split(" ");
public CountingMapData(int size) {
this.size = size < 0 ? 0 : size;
}
private static class Entry implements Map.Entry<Integer,String>{
int index;
public Entry(int index) {
this.index = index;
}
@Override
public boolean equals(Object obj) {
return Integer.valueOf(index).equals(obj);
}
@Override
public int hashCode() {
return Integer.valueOf(index).hashCode();
}
@Override
public Integer getKey() {
return index;
}
@Override
public String getValue() {
return chars[index % chars.length] + index / chars.length;
}
@Override
public String setValue(String value) {
throw new UnsupportedOperationException();
}
}
@Override
public Set<Map.Entry<Integer,String>> entrySet(){
// LinkedHashSet retains initialization order:
Set<Map.Entry<Integer,String>> entries = new LinkedHashSet<>();
for (int i = 0; i < size; i++) {
entries.add(new Entry(i));
}
return entries;
}
public static void main(String[] args) {
System.out.println(new CountingMapData(60));
}
}
这里是使用的是LinkedHashSet,而不是定制的Set类,因此享元并未完全实现。
3.Collection的功能方法
下面的表格列出了可以通过Collection执行的所有操作(不包括从Object继承而来的方法)。因此,它们也是可以通过Set或List执行的所有操作(List还有额外的功能)。Map不是继承自Collection的,所以会另行介绍。

请注意,其中不包括随机访问所选择元素的get()方法。因为Collection包括Set,而Set是自己维护内部顺序的。因此,如果想访问Collection中的元素,那就必须使用迭代器。
下面的例子展示了所有这些方法。虽然任何实现了Collection的类都可以使用这些方法,但示例中使用ArrayList,以说明各种Collection子类的“最基本的共同特性”:
package com.zjwave.thinkinjava.collection;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Collections;
import java.util.List;
public class CollectionMethods {
public static void main(String[] args) {
Collection<String> c = new ArrayList<>();
c.addAll(Countries.names(6));
c.add("ten");
c.add("eleven");
System.out.println(c);
// Make an array from the List:
Object[] array = c.toArray();
String[] str = c.toArray(new String[0]);
// Find max and min elements;this means
// different thins depending on the way
// the Comparable interface is implemented:
System.out.println("Collections.max(c) = " + Collections.max(c));
System.out.println("Collections.min(c) = " + Collections.min(c));
// Add a Collection to another Collection
Collection<String> c2 = new ArrayList<>();
c2.addAll(Countries.names(6));
c.addAll(c2);
System.out.println(c);
c.remove(Countries.DATA[0][0]);
System.out.println(c);
c.remove(Countries.DATA[1][0]);
System.out.println(c);
// Remove all components that are
// in the argument collection:
c.removeAll(c2);
System.out.println(c);
c.addAll(c2);
System.out.println(c);
// Is an element in this Collection?
String val = Countries.DATA[3][0];
System.out.println("c.contains("+val+") = " + c.contains(val));
// Is a Collection in this Collection?
System.out.println("c.containsAll(c2) = " + c.containsAll(c2));
Collection<String> c3 = ((ArrayList<String>) c).subList(3, 5);
// Keep all the elements that are in both
// c2 and c3 (an intersection of sets)
c2.retainAll(c3);
System.out.println(c2);
// Throw away all the elements
// in c2 that also appear in c2:
c2.removeAll(c3);
System.out.println("c2.isEmpty() = " + c2.isEmpty());
c = new ArrayList<>();
c.addAll(Countries.names(6));
System.out.println(c);
c.clear();//Remove all elements
System.out.println("after c.clear():" + c);
}
}

创建ArrayList来保存不同的数据集,然后向上转型为Collection,所以很明显,代码只用到了Collection接口。main()用简单的练习展示了Collection中的所有方法。
后面讲介绍List、Set和Map的各种实现,每种情况都会(以星号)标出默认的选择。
4.可选操作
执行各种不同的添加和移除的方法在Collection接口中都是可选操作。这意味着实现类并不需要为这些方法提供功能定义。
这是一种很不寻常的接口定义方式。正如你所看到的那样,接口是面向对象设计中的契约,它声明“无论你选择如何实现该接口,我保证你可以向该接口发送这些信息。”但是可选操作违反这个非常基本的原则,它声明调用某些方法将不会执行有意义的行为,相反,它们会抛出异常。这看起来好像是编译器类型安全被抛弃了!
事情并不那么糟。如果一个操作是可选的,编译器仍旧会严格要求你只能调用该接口中的方法。这与动态语言不同,动态语言可以在任何对象上调用任何方法,并且可以在运行时发现某个特定调用是否可以工作。另外,将Collection当做参数接受的大部分方法只会从Collection中读取,而Collection的读取方法都不是可选的。
为什么你会将方法定义为可选的呢?那是因为这样做可以防止在设计中出现接口爆炸的情况。容器类库的其他设计看起来总是为了描述每个主题的各种变体,而最终换上了令人困惑的接口过剩症。甚至这么做仍不能捕捉接口的各种特例,因为总是有人会发明新的接口。“未获支持的操作”这种方式可以实现Java容器类库的一个重要目标:容器应该易学易用。未获支持的操作是一种特例,可以延迟到需要时再实现。但是,为了让这种方式能够工作:
-
UnsupportedOperationException必须是一种罕见事件。即,对于大多数类来说,所有操作都应该可以工作,只有在特例中才会有未获支持的操作。在Java容器类库中确实如此,因为你在99%的时间里面使用的容器类,如ArrayList、LinkedList、HashSet和HashMap,以及其他的具体实现,都支持所有的操作。这种设计留下了一个“后门”,如果你想创建新的Collection,但是没有为Collection接口中的所有方法都提供有意义的定义,那么它仍旧适合现有的类库。
-
如果一个操作是为获支持的,那么在实现接口的时候可能就会导致UnsupportedOperationException异常,而不是将产品程序交给客户以后才出现此异常,这种情况是有道理的。毕竟,它表示编程上有错误:使用了不正确的接口实现。
值得注意的是,未获支持的操作只有在运行时才能探测到,因此它们表示动态类型检查。如果你以前使用的是像C++这样的静态类型语言,那么可能会觉得Java也只是另一种静态类型语言,但是它还具有大量的动态类型机制,因此很难说它到底是哪一种类型的语言。一旦开始注意到了这一点了,你就会看到Java中动态类型检查的其他例子。
4.1 未获支持的操作
最常见的未获支持的操作,都来源于背后由固定尺寸的数据结构支持的容器。当你用Arrays.asList()将数组转换为List时,就会得到这样的容器。你还可以通过使用Collections类中的“不可修改”的方法,选择创建任何会抛出UnsupportedOperationException的容器(Map)。下面的示例包括这两种情况:
package com.zjwave.thinkinjava.collection;
import java.util.*;
public class Unsupported {
static void test(String msg, List<String> list){
System.out.println("--- " + msg + " ---");
Collection<String> c = list;
Collection<String> subList = list.subList(1, 8);
// Copy of the sublist
Collection<String> c2 = new ArrayList<>(subList);
try {
c.retainAll(c2);
}catch (Exception e){
System.out.println("retainAll(): " + e);
}
try {
c.removeAll(c2);
}catch (Exception e){
System.out.println("removeAll(): " + e);
}
try {
c.clear();
}catch (Exception e){
System.out.println("clear(): " + e);
}
try {
c.add("X");
}catch (Exception e){
System.out.println("add(): " + e);
}
try {
c.addAll(c2);
}catch (Exception e){
System.out.println("addAll(): " + e);
}
try {
c.remove("C");
}catch (Exception e){
System.out.println("remove(): " + e);
}
// The List.set() method modifies the value but
// doesn't change the size of the data structure:
try {
list.set(0,"X");
}catch (Exception e){
System.out.println("List.set(): " + e);
}
}
public static void main(String[] args) {
List<String> list = Arrays.asList("A B C D E F G H I J K L".split(" "));
test("Modifiable Copy",new ArrayList<>(list));
test("Arrays.asList()",list);
test("unmodifiableList()", Collections.unmodifiableList(list));
}
}

因为Arrays.asList()会生成一个List,它基于一个固定大小的数组,仅支持那些不会改变数组大小的操作,对它而言是有道理的。任何会引起对底层数据结构的尺寸进行修改的方法都会产生一个UnsupportedOperationException异常,以表示对未获支持操作的调用(一个编程错误)。
注意,应该把Arrays.asList()的结果作为构造器的参数传递给任何Collection(或者使用addAll()方法,或Collections.addAll()静态方法),这样可以生成允许使用所有的方法的普通容器——这在main()中的第一个对test()的调用中得到了展示,这样的调用会产生新的尺寸可调的底层数据结构。Collections类中的“不可修改”的方法将容器包装到了一个代理中,只要你执行任何试图修改容器的操作,这个代理都会产生UnsupportedOperationException异常。使用这些方法的目标就是产生“常量”容器对象。“不可修改”的Collections方法的完整列表将在稍后介绍。
test()中的最后一个try语句块将检查作为List的一部分的set()方法。这很有趣,因为你可以看到“未获支持的操作”这一技术在粒度来的是多么方便——所产生的“接口”可以在Arrays.asList()返回的对象和Collections.unmodifiableList()返回的对象之间,在一个方法的粒度上产生变化。Arrays.asList()返回固定尺寸的List,而Collections.unmodifiableList()产生不可修改的List。正如从输出中所看到的,修改Arrays.asList()返回的List中的元素是可以的,因为这没有违反该List“尺寸固定”这一特性。但是很明显unmodifiableList()的结果在任何情况下都应该不是可修改的。如果使用的是借口,那么还需要两个附加的接口,一个具有可以工作的set()方法,另外一个没有,因为附加的接口对于Collection的各种不可修改的子类型来说是必须的。
对于将容器作为参数接受的方法,其文档应该指定哪些可选方法必须实现。
5.List的功能方法
正如你所看到的,基本的List很容易使用:大多数时候只是调用add()添加对象,使用get()一次取出一个元素,以及调用iterator()获取用于该序列的Iterator。
下面的例子中的每个方法都涵盖了一组不同的动作:
- basicTest()中包含每个List都可以执行的操作;
- iterMotion()使用Iterator便利元素;
- 对应的iterMainipulation()使用Iterator修改元素
- testVisual()用以查看List的操作效果
- 还有一些LinkedList专用的操作。
package com.zjwave.thinkinjava.collection;
import java.util.*;
public class Lists {
private static boolean b;
private static String s;
private static int i;
private static Iterator<String> it;
private static ListIterator<String> lit;
public static void basicTest(List<String> a) {
a.add(1, "x");//Add at location 1
a.add("x");// Add at end
//Add a collection
a.addAll(Countries.names(25));
//Add a collection starting at location 3:
a.addAll(3,Countries.names(25));
//Lists allow random access,which is cheap
// for ArrayList,expensive for LinkedList:
s = a.get(1);// Get (typed) object at location 1
i = a.indexOf("1");//Tell index of object
b = a.isEmpty();//Any elements inside?
it = a.iterator();//Ordinary Iterator
lit = a.listIterator();//ListIterator
lit = a.listIterator(3);//Start at location 3
i = a.lastIndexOf("1");// Last match
a.remove(1);// Remove location 1
a.remove("3"); // Remove this object
a.set(1,"y");// Set location 1 to "y"
// Keep everything that's in the argument
// (the intersection of the two sets):
a.retainAll(Countries.names(25));
i = a.size();//How big is it?
a.clear();//Remove all element
}
public static void iterMotion(List<String> a){
ListIterator<String> it = a.listIterator();
b = it.hasNext();
b= it.hasPrevious();
s = it.next();
i = it.nextIndex();
s = it.previous();
i = it.previousIndex();
}
public static void iterManipulation(List<String> a){
ListIterator<String> it = a.listIterator();
it.add("47");
// Must move to an element after add():
it.next();
// Remove the element after the newly produced one:
it.remove();
// Must move to an element after remove():
it.next();
// Change the element after the deleted one:
it.set("47");
}
public static void testVisual(List<String> a){
System.out.println(a);
List<String> b = Countries.names(25);
System.out.println("b = " + b);
a.addAll(b);
a.addAll(b);
System.out.println(a);
// Insert , remove and replace elements
// using a ListIterator
ListIterator<String> x = a.listIterator(a.size() / 2);
x.add("one");
System.out.println(a);
System.out.println(x.next());
x.remove();
System.out.println(x.next());
x.set("47");
System.out.println(a);
//Traverse the list backwards:
x = a.listIterator(a.size());
while (x.hasPrevious()){
System.out.print(x.previous() + " ");
}
System.out.println();
System.out.println("testVisual finished");
}
// There are some things that only LinkedLists can do:
public static void testLinkedList(){
LinkedList<Object> ll = new LinkedList<>();
ll.addAll(Countries.names(25));
System.out.println(ll);
// Treat it like a stack, pushing:
ll.addFirst("one");
ll.addFirst("two");
System.out.println(ll);
// Like "peeking" at the top of a stack:
System.out.println(ll.getFirst());
// Like popping a stack:
System.out.println(ll.removeFirst());
System.out.println(ll.removeFirst());
// Treat it like a queue , pulling elments
// off the tail end:
System.out.println(ll.removeLast());
System.out.println(ll);
}
public static void main(String[] args) {
// Make and fill a new list each time:"
basicTest(new LinkedList<>(Countries.names(25)));
basicTest(new ArrayList<>(Countries.names(25)));
iterMotion(new LinkedList<>(Countries.names(25)));
iterMotion(new ArrayList<>(Countries.names(25)));
iterManipulation(new LinkedList<>(Countries.names(25)));
iterManipulation(new ArrayList<>(Countries.names(25)));
testVisual(new LinkedList<>(Countries.names(25)));
testLinkedList();
}
}

在basicTest()和iterMotion()方法中,调用只是为了演示正确的语法,虽然取得了返回值,缺没有使用。某些情况则根本没有捕获返回值。使用这些方法前,应该查询JDK帮助文档,以充分了解各种方法的用途。
6.Set和存储顺序
在之前的Thinking in Java之集合(容器)基础:Set中的示例对可以用基本的Set执行的操作,提供了很好的介绍。但是那些示例很方便地使用了诸如Integer和String这样的Java预定义的类型,这些类型被设计为可以在容器内部使用。当你创建自己的类型时,要意识到Set需要一种方式来维护存储顺序,而存储顺序如何维护,则是在Set的不同实现之间会有所变化。因此,不同的Set实现不仅具有不同的行为,而且它们对于可以在特定的Set中放置的元素的类型也有不同的要求:

在HashSet上打星号表示,如果没有其他的限制,这就应该是你默认的选择,因为它对速度进行了优化。
定义hashCode()的机制将在本文稍后介绍。你必须为散列存储和树形存储都创建一个equals()方法,但是hashCode()只有在这个类将会被至于HashSet(这是有可能的,因为它通常是你的Set实现的首选)或者LinkedHashSet中时才是必须的。但是,对于良好的编程风格而言,你应该在覆盖equals()方法时,总是同时覆盖hashCode()方法。
下面的示例演示了为了成功的使用特定的Set实现类型而必须定义的方法:
package com.zjwave.thinkinjava.collection;
import java.util.HashSet;
import java.util.LinkedHashSet;
import java.util.Set;
import java.util.TreeSet;
public class TypesForSets {
static <T> Set<T> fill(Set<T> set,Class<T> type){
try {
for (int i = 0; i < 10; i++) {
set.add(type.getConstructor(int.class).newInstance(i));
}
}catch (Exception e){
throw new RuntimeException(e);
}
return set;
}
static <T> void test(Set<T> set,Class<T> type){
fill(set,type);
fill(set,type);//Try to add duplicates
fill(set,type);
System.out.println(set);
}
public static void main(String[] args) {
test(new HashSet<>(),HashType.class);
test(new LinkedHashSet<>(),HashType.class);
test(new TreeSet<>(),TreeType.class);
//Things that don't work:
test(new HashSet<>(),SetType.class);
test(new HashSet<>(),TreeType.class);
test(new LinkedHashSet<>(),SetType.class);
test(new LinkedHashSet<>(),TreeType.class);
try {
test(new TreeSet<>(),SetType.class);
}catch (Exception e){
System.out.println(e.getMessage());
}
try {
test(new TreeSet<>(),HashType.class);
}catch (Exception e){
System.out.println(e.getMessage());
}
}
}
class SetType{
int i ;
public SetType(int i) {
this.i = i;
}
@Override
public boolean equals(Object obj) {
return obj instanceof SetType && (i == ((SetType)obj).i);
}
@Override
public String toString() {
return Integer.toString(i);
}
}
class HashType extends SetType{
public HashType(int i) {
super(i);
}
@Override
public int hashCode() {
return i;
}
}
class TreeType extends SetType implements Comparable<TreeType>{
public TreeType(int i) {
super(i);
}
@Override
public int compareTo(TreeType o) {
return (o.i < i ? -1 : (o.i == i ? 0 : 1));
}
}
为了证明那些方法对于某种特定的Set是必须的,并且同时还要避免代码重复,我们创建了三个类。基类SetType只存储一个int,并且通过toString()方法产生它的值。因为所有在Set中存储的类都必须具有equals()方法,因此在基类中也有该方法。其等价性是基于这个int类型的i的值来确定的。
HashType继承自SetType,并且添加了hashCode()方法,该方法对于放置到Set的散列实现中的对象来说是必须的。
TreeType实现了Comparable接口,如果一个对象被用于任何种类的排序容器中,例如SortedSet(TreeSet是其唯一实现),那么它必须实现这个接口。注意,compareTo()中,我没有使用“简洁明了”的形式return i - i2,因为这是一个常见的编程错误,它只有在i和i2都是无符号的int时才能工作。对于Java的有符号int,它就会出错,因为int不够大,不足以表现两个有符号int的差。例如i是很大的正整数,而j是很大的负整数吗,i-j就会溢出并返回负值,这就不正确了。
你通常会希望compareTo()方法可以产生于equals()方法一致的自然排序。如果equals()对于某个特定比较产生true,那么compareTo()对于该比较应该返回0,如果equals()对于某个比较产生false,那么compareTo()对于该比较应该返回非0值。
在TypesForSets中,fill()和test()方法都是用泛型定义的,这是为了避免代码重复。为了验证某个Set的行为,test()会在被测Set上调用fill()三次,尝试着在其中引入重复对象。fill()方法可以接受任何类型的Set,以及其相同类型Class对象,它使用Class对象来发现并接受int参数的构造器,然后调用该构造器将元素添加到Set中。
从输出中可以看到,HashSet以某种神秘的顺序保存所有的元素,LinkedHashSet按照元素插入的顺序保存元素,而TreeSet按照排序顺序维护元素(按照compareTo()的实现方式,这里维护的是降序)。
如果我们尝试着将没有恰当地支持必须的操作的类型用于需要这些方法的Set,那么就会有大麻烦了。对于没有重新定义hashCode()方法时的SetType或TreeType,如果将它们放置到任何散列实现中都会产生重复值,这样就违反了Set的基本契约。这相当烦人,因为这甚至不会有运行时错误。但是,默认的hashCode()是合法的,因此这是合法的行为,即便它不正确。确保这种程序的正确性的唯一可靠方法就是将单元测试合并到你的构建系统中。
如果我们尝试着在TreeSet中使用没有实现Comparable的类型,那么你将会得到更确定的结果:在TreeSet试图将该对象当做Comparable使用时,将抛出一个异常。
6.1 SortedSet
SortedSet中的元素可以保证处于排序状态,这使得它可以通过在SortedSet接口中的下列方法提供附加功能:
- Comparator comparator()返回当前Set使用的Comparator;或者返回null,表示以自然方式排序。
- Object first()返回容器中的第一个元素。
- Object last()返回容器中的最后一个元素。
- subSet(fromElement, toElement)生成此Set的子集,范围从fromElement(包含)到toElement(不包含)。
- headSet(toElement)生成此Set的子集,由小于toElement的元素组成。
- tailSet(fromElement)生成此Set的子集,由大于或等于fromElement的元素组成。
下面是一个简单的示例:
package com.zjwave.thinkinjava.collection;
import java.util.Collections;
import java.util.Iterator;
import java.util.SortedSet;
import java.util.TreeSet;
public class SortedSetDemo {
public static void main(String[] args) {
SortedSet<String> sortedSet = new TreeSet<>();
Collections.addAll(sortedSet,"one two three four five six seven eight".split(" "));
System.out.println(sortedSet);
String low = sortedSet.first();
String high = sortedSet.last();
System.out.println(low);
System.out.println(high);
Iterator<String> it = sortedSet.iterator();
for (int i = 0; i < 6; i++) {
if(i == 3){
low = it.next();
}else if(i == 6){
high = it.next();
}else{
it.next();
}
}
System.out.println(low);
System.out.println(high);
System.out.println(sortedSet.subSet(low,high));
System.out.println(sortedSet.headSet(high));
System.out.println(sortedSet.tailSet(low));
}
}
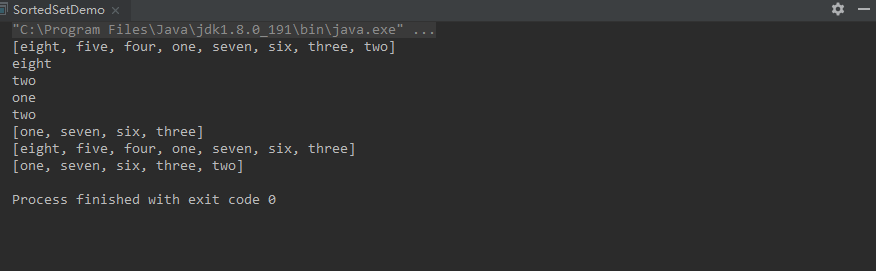
注意,SortedSet的意思是“按对象的比较函数对元素排序”,而不是指“元素插入的次序”。插入顺序可以用LinkedHashSet来保存。
7.队列
除了并发应用,Queue在Java SE5中仅有的两个实现是LinkedList和PriorityQueue,它们的差异在于排序行为而不是性能。下面是涉及Queue实现的大部分操作的基本示例(并非所有的操作在本例中都能工作),包括基于并发的Queue。你可以将元素从队列的一端插入,并于另一端将它们抽取出来:
package com.zjwave.thinkinjava.collection;
import com.zjwave.thinkinjava.generics.Generator;
import java.util.LinkedList;
import java.util.PriorityQueue;
import java.util.Queue;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ConcurrentLinkedDeque;
import java.util.concurrent.LinkedBlockingDeque;
import java.util.concurrent.PriorityBlockingQueue;
public class QueueBehavior {
private static int count = 10;
static <T> void test(Queue<T> queue, Generator<T> gen){
for (int i = 0; i < count; i++) {
queue.offer(gen.next());
}
while (queue.peek() != null){
System.out.print(queue.remove() + " ");
}
System.out.println();
}
static class Gen implements Generator<String>{
String[] s = ("one two three four five six seven eight nine ten").split(" ");
int i;
@Override
public String next() {
return s[i++];
}
}
public static void main(String[] args) {
test(new LinkedList<>(),new Gen());
test(new PriorityQueue<>(),new Gen());
test(new ArrayBlockingQueue<>(count),new Gen());
test(new ConcurrentLinkedDeque<>(),new Gen());
test(new LinkedBlockingDeque<>(),new Gen());
test(new PriorityBlockingQueue<>(),new Gen());
}
}
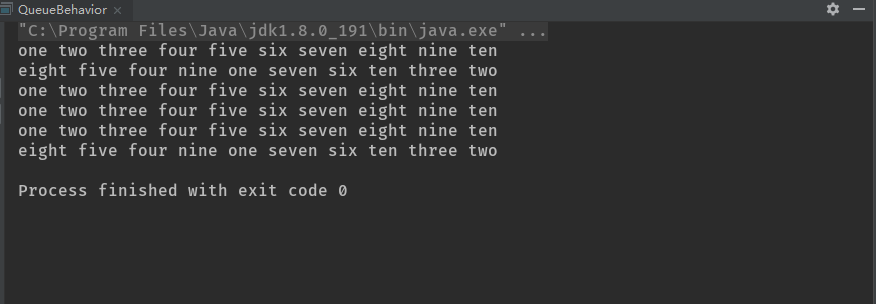
你可以看到,除了优先级队列,Queue将精确地按照元素被置于Queue中的顺序产生它们。
7.1 优先级队列
在之前的Thinking in Java之集合(容器)基础:Queue曾给出过优先级队列的一个简单介绍。其中更有趣的问题的to-do列表,该列表中每个对象都包含一个字符串下和一个主要的以及次要的优先级值。该列表的排序顺序也是通过实现Comparable而进行控制的:
package com.zjwave.thinkinjava.collection;
import java.util.PriorityQueue;
public class ToDoList extends PriorityQueue<ToDoList.ToDoItem> {
static class ToDoItem implements Comparable<ToDoItem>{
private char primary;
private int secondary;
private String item;
public ToDoItem(char primary, int secondary, String item) {
this.primary = primary;
this.secondary = secondary;
this.item = item;
}
@Override
public int compareTo(ToDoItem o) {
if(primary > o.primary){
return +1;
}
if(primary == o.primary){
if(secondary > o.secondary){
return +1;
}else if(secondary == o.secondary){
return 0;
}
}
return -1;
}
@Override
public String toString() {
return Character.toString(primary) + secondary + ": " + item;
}
}
public void add(String td,char pri,int sec){
add(new ToDoItem(pri,sec,td));
}
public static void main(String[] args) {
ToDoList toDoList = new ToDoList();
toDoList.add("Empty Trash",'C',4);
toDoList.add("Feed dog",'A',2);
toDoList.add("Feed bird",'B',7);
toDoList.add("Mow lawn",'C',3);
toDoList.add("Water lawn",'A',1);
toDoList.add("Feed cat",'B',1);
while (!toDoList.isEmpty()){
System.out.println(toDoList.remove());
}
}
}
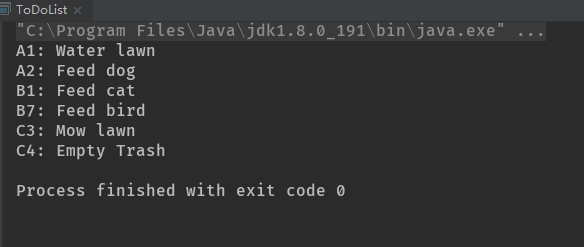
你可以看到各个项的排序是如何因为使用了优先级队列而得以自动发生的。
7.2 双向队列
双向队列(双端队列)就像是一个队列,但是你可以在任何一端添加或移除元素。在LinkedList中包含支持双向队列的方法,Deque接口是从JDK1.6开始才出现在Java类库中的:
package com.zjwave.thinkinjava.collection;
import java.util.Deque;
import java.util.LinkedList;
public class DequeTest {
static void fillTest(Deque<Integer> deque){
for (int i = 20; i < 27; i++) {
deque.addFirst(i);
}
for (int i = 50; i < 55; i++) {
deque.addLast(i);
}
}
public static void main(String[] args) {
Deque<Integer> di = new LinkedList<>();
fillTest(di);
System.out.println(di);
while (di.size() != 0){
System.out.print(di.removeLast() + " ");
}
}
}

你不太可能在两端都放入元素并抽取它们,因此,Deque不如Queue那样常用。
8.理解Map
正如你在Thinking in Java之集合(容器)基础:Map所学到的,映射表(也成为关联数组)的基本思想是它维护的是键-值(对)关联,因此你可以使用键来查找值。标准的Java类库包含了Map的几种基本实现,包括:HashMap,TreeMap,LinkedHashMap,WeakHashMap,ConcurrentHashMap,IdentityHashMap。它们都有同样的基本接口Map,但是行为特性各不相同,这表现在在效率、键值对的保存及呈现次序、对象的保存周期、映射表如何在多线程程序中工作和判定“键”等价的策略等方面。Map接口实现的数量应该可以让你感觉到这种工具的重要性。
你可以获得对Map更深入的理解,这有助于观察关联数组是如何创建的。下面是一个极其简单的实现:
package com.zjwave.thinkinjava.collection;
public class AssociativeArray<K,V> {
private Object[][] pairs;
private int index;
public AssociativeArray(int length) {
pairs = new Object[length][2];
}
public void put(K key,V value){
if(index >= pairs.length){
throw new ArrayIndexOutOfBoundsException();
}
pairs[index++] = new Object[]{key,value};
}
@SuppressWarnings("unchecked")
public V get(K key){
for (int i = 0; i < index; i++) {
if(key.equals(pairs[i][0])){
return (V) pairs[i][1];
}
}
return null;//Did not find key
}
@Override
public String toString() {
StringBuilder result = new StringBuilder();
for (int i = 0; i < index; i++) {
result.append(pairs[i][0].toString());
result.append(" : ");
result.append(pairs[i][1].toString());
if(i < index -1){
result.append("\n");
}
}
return result.toString();
}
public static void main(String[] args) {
AssociativeArray<String, String> map = new AssociativeArray<>(6);
map.put("sky","blue");
map.put("grass","green");
map.put("ocean","dancing");
map.put("tree","tall");
map.put("earth","brown");
map.put("sun","warm");
try {
map.put("extra","object");
}catch (ArrayIndexOutOfBoundsException e){
System.out.println("Too many objects!");
}
System.out.println(map);
System.out.println(map.get("ocean"));
}
}
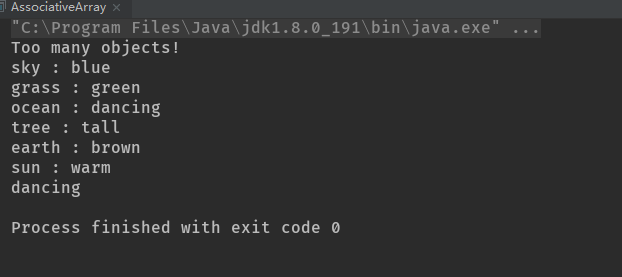
关联数组中的基本方法是put()和get(),但是为了容易显示,toString()方法被覆盖为可以打印键-值对。为了展示它可以工作,main()用字符串对加载了一个AssociativeArray,并打印了所产生的映射表,随后是获取一个值的get()。
为了使用get()方法,你需要传递想要查找的key,然后它会将与之相关联的值作为结果返回,或者在找不到的情况下返回null。get()方法使用的可能是能想象到的效率最差的方式来定位值的:从数组的头部开始,使用equals()方法依次比较键。但这里的关键是简单性而不是效率。
因此上面的版本是说明性的,但缺乏效率,并且由于具有固定的尺寸而显得很不灵活。幸运的是,在java.util中的各种Map都没有这些问题,并且都可以替代到上面的实例中。
8.1 性能
性能是映射表中的一个重要问题,当在get()中使用线性搜索时,执行速度会相当地慢,而这正是HashMap提高速度的地方。HashMap使用了特殊的值,称作散列码,来取代对键的缓慢搜索。散列码是“相对唯一”的、用以代表对象的int值,它是通过将该对象的某些信息进行转换而生成的。hashCode()是根类Object中的方法,因此所有的Java对象都能产生散列码。HashMap就是使用对象的hashCode()进行快速查询的,此方法能够显著提高性能。
下面是基本的Map实现。在HashMap上打星号表示如果没有其他的限制,它就应该成为你的默认选择,因为它对速度进行了优化。其他实现强调了其他的特性,因此都不如HashMap快。

散列是映射中存储元素时最常用的方式。稍后你将会了解散列机制是如何工作的。
对Map中使用的键的要求与对Set中的元素的要求一样,在TypesForSets.java中展示了这一点。
- 任何键都必须具有equals()方法
- 如果键被用于散列Map,那么它必须还具有恰当的hashCode()方法
- 如果键被用于TreeMap,那么它必须实现Comparable
下面的示例展示了通过Map接口可用的操作,这里使用了前面定义过的CountingMapData测试数据集:
package com.zjwave.thinkinjava.collection;
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
public class Maps {
public static void printKeys(Map<Integer, String> map) {
System.out.print("Size = " + map.size() + ", ");
System.out.print("Keys: ");
System.out.print(map.keySet());//Produce a Set of the keys
}
public static void test(Map<Integer, String> map) {
System.out.println(map.getClass().getSimpleName());
map.putAll(new CountingMapData(25));
// Map has 'Set' behavior for keys
map.putAll(new CountingMapData(25));
printKeys(map);
// Producing a Collection of the values:
System.out.print("Values: ");
System.out.println(map.values());
System.out.println(map);
System.out.println("map.containsKey(11): " + map.containsKey(11));
System.out.println("map.get(11): " + map.get(11));
System.out.println("map.containsValue(\"F0\"): " + map.containsValue("F0"));
Integer key = map.keySet().iterator().next();
System.out.println("First key in map" + key);
map.remove(key);
printKeys(map);
map.clear();
System.out.println("map.isEmpty(): " + map.isEmpty());
map.putAll(new CountingMapData(25));
// Operations on the Set change the Map:
map.keySet().removeAll(map.keySet());
System.out.println("map.isEmpty(): " + map.isEmpty());
}
public static void main(String[] args) {
test(new HashMap<>());
test(new TreeMap<>());
test(new LinkedHashMap<>());
test(new IdentityHashMap<>());
test(new ConcurrentHashMap<>());
test(new WeakHashMap<>());
}
}

printKeys()展示了如何生成Map的Collection视图。keySet()方法返回由Map的键组成的Set。因为在Java SE5提供了改进的打印支持,你可以直接打印values()方法的结果,该方法会产生一个包含Map中所有的“值”的Collection。(注意,键必须是唯一的,而值可以有重复。)由于这些Collection背后是由Map支持的,所以对Collection的任何改动都会反映到与之相关联的Map。
此程序的剩余部分提供了每种Map操作的简单示例,并测试了每种基本类型的Map。
8.2 SortedMap
使用SortedMap(TreeMap是其现阶段唯一实现),可以确保键处于排序状态。这使得它具有额外的功能,这些功能由SortedMap接口中的下列方法提供:
- Comparator comparator():返回当前Map使用的Comparator;或者返回null,表示以自然方式排序。
- T firstKey():返回Map中的第一个键。
- T lastKey():返回Map中的最末一个键。
- SortedMap subMap(fromKey, toKey):生成此Map的子集,范围由fromKey(包含)到toKey(不包含)的键确定。
- SortedMap headMap(toKey):生成此Map的子集,由键小于toKey的所有键值对组成。
- SortedMap tailMap(fromKey):生成此Map的子集,由键大于或等于fromKey的所有键值对组成。
下面的例子与SortedSetDemo.java相似,演示了TreeMap新增的功能:
package com.zjwave.thinkinjava.collection;
import java.util.Iterator;
import java.util.TreeMap;
public class SortedMapDemo {
public static void main(String[] args) {
TreeMap<Integer, String> sortedMap = new TreeMap<>(new CountingMapData(10));
System.out.println(sortedMap);
Integer low = sortedMap.firstKey();
Integer high = sortedMap.lastKey();
System.out.println(low);
System.out.println(high);
Iterator<Integer> it = sortedMap.keySet().iterator();
for (int i = 0; i <= 6; i++) {
if(i == 3){
low = it.next();
}else if(i == 6){
high = it.next();
}else {
it.next();
}
}
System.out.println(low);
System.out.println(high);
System.out.println(sortedMap.subMap(low,high));
System.out.println(sortedMap.headMap(high));
System.out.println(sortedMap.tailMap(low));
}
}

此处,键值对是按键的次序排列的。TreeMap中的次序是有意义的,因此“位置”的概念才有意义,所以才能取得第一个和最后一个元素,并且可以提取Map的子集。
8.3 LinkedHashMap
为了提高速度,LinkedHashMap散列化所有的元素,但还是在遍历键值对时,却又以元素插入顺序返回键值对(System.out.println()会迭代遍历该映射,因此可以看到遍历的结果)。此外,可以在构造器中设定LinkedHashMap,使之采用基于访问的最近最少使用(LRU)算法,于是没有被访问过的(可被看作需要删除的)元素就会出现在队列的前面。对于需要定期清理元素以节省空间的程序来说,此功能使得程序很容易得以实现。下面就是一个简单的例子,它演示了LinkedHashMap的这两种特点:
package com.zjwave.thinkinjava.collection;
import java.util.LinkedHashMap;
public class LinkedHashMapDemo {
public static void main(String[] args) {
LinkedHashMap<Integer, String> linkedMap = new LinkedHashMap<>(new CountingMapData(9));
System.out.println(linkedMap);
//Least-recently-used order:
linkedMap = new LinkedHashMap<>(16,0.75f,true);
linkedMap.putAll(new CountingMapData(9));
System.out.println(linkedMap);
for (int i = 0; i < 6; i++) {
linkedMap.get(i);
}
System.out.println(linkedMap);
linkedMap.get(0);
System.out.println(linkedMap);
}
}
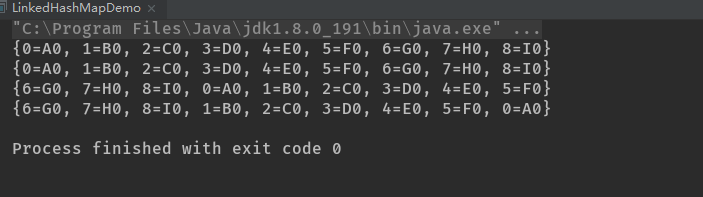
在输出中可以看到,键值对是以插入的顺序进行遍历的,甚至LRU算法的版本也是如此。但是,在LRU版本中,在(只)访问过前面六个元素后,最后三个元素移到了队列前面。然后再一次访问元素“0”时,它就被移到队列后端了。
9.散列与散列码
如果是标准类库中的类被用作HashMap的键。会用得很好,因为它具备了键所需的全部性质。
当你自己创建用作HashMap的键的类,有可能会忘记在其中放置必须的方法,而这是通常会犯的一个错误。例如,考虑一个天气预报系统,将Groundhog(土拨鼠)对象与Prediction(预报)对象联系起来。这看起来很简单。创建这两个类,使用Groundhog作为键,Prediction作为值:
package com.zjwave.thinkinjava.collection;
public class Groundhog {
protected int number;
public Groundhog(int number) {
this.number = number;
}
@Override
public String toString() {
return "Groundhog #" + number;
}
}
package com.zjwave.thinkinjava.collection;
import java.util.Random;
public class Prediction {
private static Random rand = new Random(47);
private boolean shadow = rand.nextDouble() > 0.5;
@Override
public String toString() {
if(shadow){
return "Six more weeks of Winter!";
}else {
return "Early Spring";
}
}
}
package com.zjwave.thinkinjava.collection;
import java.lang.reflect.Constructor;
import java.util.HashMap;
import java.util.Map;
public class SpringDetector {
//Uses a Groundhog or class derived from Groundhog:
public static <T extends Groundhog> void detectSpring(Class<T> type) throws Exception {
Constructor<T> ghog = type.getConstructor(int.class);
Map<Groundhog, Prediction> map = new HashMap<>();
for (int i = 0; i < 10; i++) {
map.put(ghog.newInstance(i), new Prediction());
}
System.out.println("map = " + map);
Groundhog gh = ghog.newInstance(3);
System.out.println("Looking up prediction for " + gh);
if(map.containsKey(gh)){
System.out.println(map.get(gh));
}else {
System.out.println("Key not found: " + gh);
}
}
public static void main(String[] args) throws Exception{
detectSpring(Groundhog.class);
}
}
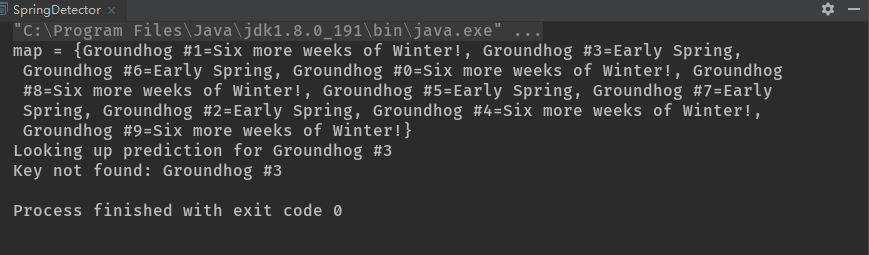
每个Groundhog被给予一个标识数字,于是可以在HashMap中这样查找Prediction:“给我与Groundhog#3相关的Prediction。”Prediction类包含一个boolean值和一个toString()方法。boolean值使用java.util.Random()来初始化;而toString()方法则解释结果。detectSpring()方法使用反射机制来实例化及使用Groundhog或任何从Groundhog派生出来的类。如果我们为解决当前的问题从Groundhog继承创建了一个新类型的时候,detectSpring()方法使用的这个技巧就变得很有用了。
首先会使用Groundhog和与之相关联的Prediction填充HashMap,然后打印此HashMap,以便可以观察它是否被填入了一些内容。然后使用标识数字为3的Groundhog作为键,查找与之相对应的预报内容(可以看到,它一定是在Map中)。
这看起来够简单了,但是它不工作——它无法找到数字3这个键。问题出来Groundhog自动地继承自基类Object,所以这里使用Object的hashCode()方法生成散列码,而它默认是使用对象的地址计算散列码。因此,由Groundhog(3)生成的第一个实例的散列码与由Groundhog(3)生成的第二个实例的散列码是不同的,而我们正式使用后者进行查找的。
可能你会认为,只需编写恰当的hashCode()方法的覆盖版本即可。但是它仍然无法正常运行,除非你同时覆盖equals()方法,它也是Object的一部分。HashMap使用equals()判断当前的键是否与表中存在的键相同。
正确的equals()方法必须满足下列5个条件:
- 自反性。对任意x,x.equals(x)一定返回true。
- 对称性。对任意x和y,如果y.equals(x)返回true,则x.equals(y)也返回true。
- 传递性。对任意x、y、z,如果有x.equals(y)返回true,y.equals(z)返回true,则x.equals(z)一定返回true。
- 一致性。对任意x和y,如果对象中用于等价比较的信息没有改变,那么无论调用x.equals(y)多少次,返回的结果应该保持一致,要么一直是true,要么一直是false。
- 对任何不是null的x,x.equals(null)一定返回false。
再次强调,默认的Object.equals()只是比较对象的地址,所以一个Groundhog(3)并不等于另一个Groundhog(3)。因此,如果要使用自己的类作为HashMap的键,必须同时重载hashCode()和equals(),如下所示:
package com.zjwave.thinkinjava.collection;
public class Groundhog2 extends Groundhog {
public Groundhog2(int number) {
super(number);
}
@Override
public int hashCode() {
return number;
}
@Override
public boolean equals(Object obj) {
return obj instanceof Groundhog2 && (number == ((Groundhog2) obj).number);
}
}
package com.zjwave.thinkinjava.collection;
public class SpringDetector2 {
public static void main(String[] args) throws Exception {
SpringDetector.detectSpring(Groundhog2.class);
}
}
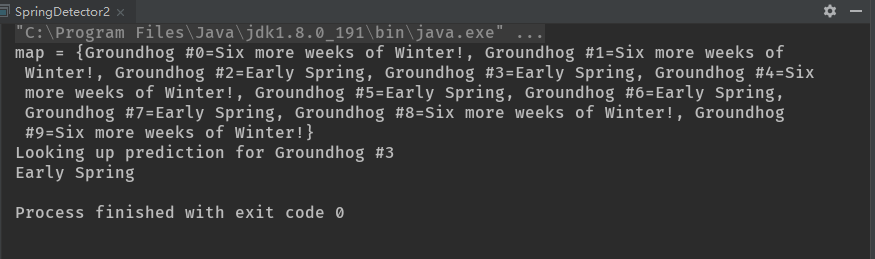
Groundhog2.hashCode()返回Groundhog的标识数字(编号)作为散列码。在此例中,程序员负责确保不同的Groundhog具有不同的编号。hashCode()并不需要总是能够返回唯一的标识码(稍后读者会理解其原因),但是equals()是判断Groundhog的号码,所以作为HashMap中的键,如果两个Groundhog2对象具有相同的Groundhog编号,程序就出错了。
尽管看起来equals()方法只是检查其参数是否是Groundhog2的实例,但是instanceof悄悄地检查了此对象是否为null,因此如果instanceof左边的参数为null,它会返回false。如果equals()的参数部位null且类型正确,则基于每个对象中实际的number数值进行比较。从输出中可以看到,现在的方式是正确的。
当在HashSet中使用自己的类作为键时,也必须注意这个问题。
9.1 理解hashCode()
前面的例子只是正确解决问题的第一步。它只说明,如果不为你的键覆盖hashCode()和equals()方法,那么使用散列的数据结构(HashSet,HashMap,LinkedHashSet或LinkedHashMap)就无法正确处理你的键。然而,要很好地解决此问题,你必须了解这些数据结构的内部构造。
首先,使用散列的目的在于:想要使用一个对象来查找另一个对象。不过使用TreeMap或者你自己实现的Map也可以达到此目的。与散列实现相反,下面的示例用一对ArrayList实现了一个Map。与AssociativeArray.java不同,这其中包含了Map接口的完整实现,因此提供了entrySet()方法:
package com.zjwave.thinkinjava.collection;
import java.util.*;
public class SlowMap<K,V> extends AbstractMap<K, V> {
private List<K> keys = new ArrayList<>();
private List<V> values = new ArrayList<>();
@Override
public V put(K key, V value) {
V oldValue = get(key);//The old value or null
if(!keys.contains(key)){
keys.add(key);
values.add(value);
}else{
values.set(keys.indexOf(key),value);
}
return oldValue;
}
@Override
public V get(Object key) {
if(!keys.contains(key)){
return null;
}
return values.get(keys.indexOf(key));
}
@Override
public Set<Entry<K, V>> entrySet() {
Set<Map.Entry<K,V>> set = new HashSet<>();
Iterator<K> ki = keys.iterator();
Iterator<V> vi = values.iterator();
while (ki.hasNext()){
set.add(new MapEntry<>(ki.next(),vi.next()));
}
return set;
}
public static void main(String[] args) {
SlowMap<String,String> m =new SlowMap<>();
m.putAll(Countries.capitals(15));
System.out.println(m);
System.out.println(m.get("BULGARIA"));
System.out.println(m.entrySet());
}
}
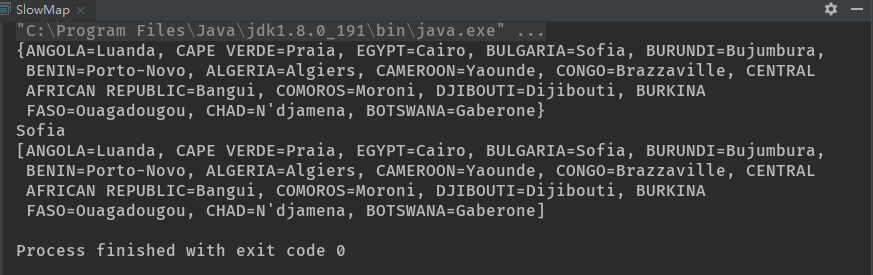
put()方法只是将键与值放入相应的ArrayList。为了与Map接口保持一致,它必须返回旧的键,或者在没有任何旧键的情况下返回null。
同样遵循了Map规范,get()会在键不在SlowMap中的时候产生null。如果键存在,它将被用来查找表示它在keys列表中的位置的数值型索引,并且这个数字被用作索引来产生与values列表相关联的值。注意,在get()中key的类型是Object,而不是你所期望的参数化类型K(并且是在AssociativeArray.java中真正使用的类型)。这是将泛型注入到Java语言中的时刻如此之晚所导致的结果——如果泛型是Java语言最初就具备的属性,那么get()就可以执行其参数的类型。
Map.entrySet()方法必须产生一个Map.Entry对象集。但是,Map.Entry是一个接口,用来描述依赖于实现的结构,因此,如果你想要创建自己的Map类型,就必须同时定义Map.Entry的实现:
package com.zjwave.thinkinjava.collection;
import java.util.Map;
public class MapEntry<K,V> implements Map.Entry<K,V> {
private K key;
private V value;
public MapEntry(K key, V value) {
this.key = key;
this.value = value;
}
@Override
public K getKey() {
return key;
}
@Override
public V getValue() {
return value;
}
@Override
public V setValue(V v) {
V result = v;
value = v;
return result;
}
@Override
public int hashCode() {
return (key == null ? 0 : key.hashCode()) ^ (value == null ? 0 : value.hashCode());
}
@Override
public boolean equals(Object obj) {
if(!(obj instanceof MapEntry)){
return false;
}
MapEntry me = (MapEntry)obj;
return (key == null ? me.getKey() == null : key.equals(me.getKey()))
&& (value == null ? me.getValue() == null : value.equals(me.getValue()));
}
@Override
public String toString() {
return key + "=" + value;
}
}
这里,这个被称为MapEntry的十分简单的类可以保存和读取键与值,它在entrySet()中用来产生键-值对Set。注意entrySet()使用了HashSet来保存键-值对,并且MapEntry采用了一种简单的方式,即只使用key的hashCode()方法。尽管这个解决方案非常简单,并且看起来是SlowMap.main()的琐碎测试中可以工作,但是这并不是一个恰当的实现,因为它创建了键和值的副本。entrySet()的恰当实现应该在Map中提供视图,而不是副本,并且这个视图允许对原始映射表进行修改(副本就不行)。
注意,在MapEntry中的equals()方法必须同时检查键和值,而hashCode()方法的含义稍后就会介绍。SlowMap的内容的String表示是由在AbstractMap中定义的toString()方法自动产生的。
9.2 为速度而散列
SlowMap.java说明了创建一种新的Map并不困难。但是正如它的名称SlowMap所示,它不会很快,所以如果有更好的选择,就应该放弃它。它的问题在于对键的查询,键没有按照任何特定顺序保存,所以只能使用简单的线性查询,而线性查询是最慢的查询方式。
散列的价值在于速度:散列使得查询得以快速进行。由于瓶颈位于键的查询速度,因此解决方案之一就是保持键的排序状态,然后使用Collections.binarySearch()进行查询(有一个练习会带领读者走完这个过程)。
散列则更进一步,它将键保存在某处,以便能够很快找到。存储一组元素最快的数据结构是数组,所以使用它来表示键的信息(请小心留意,我是说键的信息,而不是键本身)。但是因为数组不能调整容量,因此就有一个问题:我们希望在Map中保存数量不确定的值,但是如果键的数量被数组的容量限制了,该怎么办呢?
答案就是:数组并不保存键本身。而是通过键生成一个数字,将其作为数组的下标。这个数字就是散列码,由定义在Object中的、且可能由你的类覆盖的hashCode()方法(在计算机科学的术语中称为散列函数)生成。
为解决数组容量被固定的问题,不同的键可以产生相同的下标。也就是说,可能会有冲突。因此,数组多大就不重要了,任何键总能在数组中找到它的位置。
于是,查询一个值的过程首先就是计算散列码,然后使用散列码查询数组。如果能够保证没有冲突(如果值的数量是固定的,那么就有可能),那可就有了一个完美的散列函数,但是这种情况只是特例。通常,冲突由外部链接处理:数组并不直接保存值,而是保存值的list。然后对list中的值使用equals()方法进行线性查询。这部分的查询自然会比较慢,但是,如果散列函数好的话,数组的每个位置就只有较少的值。因此,不是查询整个list,而是快速地跳到数组的某个位置,只对很少的元素进行比较。这便是HashMap会如此快的原因。
理解了散列的原理,我们就能够实现一个简单的散列Map了:
package com.zjwave.thinkinjava.collection;
import java.util.*;
public class SimpleHashMap<K,V> extends AbstractMap<K,V> {
// Choose a prime number for the hash table
// size , to achieve a uniform distribution:
static final int SIZE = 997;
// You can't have a physical array of generics
// but you can upcast to one:
@SuppressWarnings("unchecked")
LinkedList<MapEntry<K,V>>[] buckets = new LinkedList[SIZE];
@Override
public V put(K key, V value) {
V oldValue = null;
int index = Math.abs(key.hashCode()) % SIZE;
if(buckets[index] == null){
buckets[index] = new LinkedList<>();
}
LinkedList<MapEntry<K, V>> bucket = buckets[index];
MapEntry<K,V> pair = new MapEntry<>(key,value);
boolean found = false;
ListIterator<MapEntry<K, V>> it = bucket.listIterator();
while (it.hasNext()){
MapEntry<K, V> iPair = it.next();
if(iPair.getKey().equals(key)){
oldValue = iPair.getValue();
it.set(pair);//Replace old with new
found = true;
break;
}
}
if(!found){
buckets[index].add(pair);
}
return oldValue;
}
@Override
public V get(Object key) {
int index = Math.abs(key.hashCode()) % SIZE;
if(buckets[index] == null){
return null;
}
for (MapEntry<K, V> iPair : buckets[index]) {
if(iPair.getKey().equals(key)){
return iPair.getValue();
}
}
return null;
}
@Override
public Set<Entry<K, V>> entrySet() {
HashSet<Entry<K, V>> set = new HashSet<>();
for (LinkedList<MapEntry<K, V>> bucket : buckets) {
if(bucket == null){
continue;
}
for (MapEntry<K, V> mpair : bucket) {
set.add(mpair);
}
}
return set;
}
public static void main(String[] args) {
SimpleHashMap<String, String> m = new SimpleHashMap<>();
m.putAll(Countries.capitals(25));
System.out.println(m);
System.out.println(m.get("ERITREA"));
System.out.println(m.entrySet());
}
}

由于散列表中的“槽位”(slot)通常称为桶位(bucket),因此我们将表示实际散列表的数组命名为bucket。为使散列分布均匀,桶的数量通常使用质数。注意,为了能够自动处理冲突,使用了一个LinkedLsit数组;每一个新的元素只是直接添加到list末尾的某个特定桶位中。即使Java不允许你创建泛型数组,那你也可以创建指向这种数组的引用。这里,向上转型为这种数组是很方便的,这样可以防止在后面的代码中进行额外的转型。
对于put()方法,hashCode()将针对键而被调用,并且其结果被强制转换为正数。为了使产生数字适合bucket数组的大小,取模操作符将按照该数组的尺寸取模。如果数组的某个位置是null,这表示还没有元素被散列至此,所以,为了保存刚散列到该定位的对象,需要创建一个新的LinkedList。一般的过程是,查看当前位置的list中是否有相同的元素,如果有,则将旧的值赋给oldValue,然后用新的值取代旧的值。标记found用来跟踪是否找到(相同的)旧的键值对,如果没有,则将新的对添加到list的末尾。
get()方法按照与put()方法相同的方式计算在bucket数组中的索引(这很重要,因为这样可以保证两个方法可以计算出相同的位置)如果此位置有LinkedList存在,就对其进行查询。
注意,这个实现并不意味着对性能进行了调优,它只是想要展示散列映射表执行的各种操作。如果你浏览一下java.util.HashMap的源代码,你就会看到一个调过优的实现。同样,为了简单,SimpleHashMap使用了与SlowMap相同的方式来实现entrySet(),这个方法有些过于简单,不能用于通用的Map。
9.3 覆盖hashCode()
在明白了如何散列之后,编写自己的hashCode()就更有意义了。
首先,你无法控制bucket数组的下标值的产生。这个值依赖于具体的HashMap对象的容量,而容量改变与容器的充满程度和负载因子(稍后会介绍这个术语)有关。hashCode()生成的结果,经过处理后成为桶位的下标(在SimpleHashMap中,只是对其取模,模数为bucket数组的大小)。
设计hashCode()时最重要的因素就是:无论何时,对同一个对象调用hashCode()都因该生成同样的值。如果在将一个对象用put()添加进HashMap时产生一个hashCode()值,而用get()取出时却产生了另一个hashCode()值,那么就无法重新取得该对象了。所以,如果你的hashCode()方法依赖于对象中易变的数据,用户就要当心了,因为此数据发生变化时,hashCode()就会生成一个不同的散列码,相当于产生了一个不同的键。
此外,也不应该使hashCode()依赖于具有唯一性的对象信息,尤其是使用this的值,这只能产生很糟糕的hashCode()。因为这样做无法生成一个新的键,使之与put()中原始的键值对中的键相同。这正是SpringDetector.java问题所在,因为它默认的hashCode()使用的是对象的地址。所以,应该使用对象内有意义的识别信息。
下面以String类为例。String有个特地奥:如果程序中有多个String对象,都包含相同的字符串序列,那么这些String对象都映射到同一块内存区域。所以new String("hello")生成的两个实例,虽然是相互独立的,但是对它们使用hashCode()应该生成同样的结果。通过下面的程序可以看到这种情况:
package com.zjwave.thinkinjava.collection;
public class StringHashCode {
public static void main(String[] args) {
String[] hellos = "Hello Hello".split(" ");
System.out.println(hellos[0].hashCode());
System.out.println(hellos[1].hashCode());
}
}

对于String而言,hashCode()明显是基于String的内容的。
因此,要想使hashCode()实用,它必须速度快,并且必须有意义。也就是说,它必须基于对象的内容生成散列码。记得吗,散列码不必是独一无二的(应该更关注生成速度,而不是唯一性),但是通过hashCode()和equals(),必须能够完全确定对象的身份。
因为在生成桶的下标前,hashCode()还需要做进一步的处理,所以散列码的生成范围并不重要,只要是int即可。
还有另一个影响因素:好的hashCode()应该产生分布均匀的散列码。如果散列码都集中在一块,那么HashMap或者HashSet在某些区域的负载会很重,这样就不如分布均匀的散列函数快。
在Effective Java Programming Language Guide(Addison-Wesley 2001)这本书中,Joshua Bloch为怎样写出一份像样的hashCode()给出了基本的指导:
- 给int变量result赋予某个非零值常量,例如17。
- 为对象内每个有意义的域f(即每个可以做equals()操作的域)计算出一个int散列码c:
- 合并计算得到的散列码:result = 37 * result + c;
- 返回result。
- 检查hashCode()最后生成的结果,确保相同的对象有相同的散列码。

下面便是遵循这些指导的一个例子:
package com.zjwave.thinkinjava.collection;
import java.util.*;
public class CountedString {
private static List<String> created = new ArrayList<>();
private String s;
private int id = 0;
public CountedString(String s) {
this.s = s;
created.add(s);
// id is the total number of instances
// of this string in use by CountedString:
for (String s2 : created) {
if(s2.equals(s)){
id++;
}
}
}
@Override
public String toString() {
return "String: " + s + " id: " + id + " hashCode(): " + hashCode();
}
@Override
public int hashCode() {
// The very simple approach:
// return s.hashCode() * id:
// Using Joshua Bloch's recipe:
int result = 17;
result = 37 * result + s.hashCode();
result = 37 * result + id;
return result;
}
@Override
public boolean equals(Object obj) {
return obj instanceof CountedString && s.equals(((CountedString) obj).s) && id == ((CountedString) obj).id;
}
public static void main(String[] args) {
Map<CountedString,Integer> map = new HashMap<>();
CountedString[] cs = new CountedString[5];
for (int i = 0; i < cs.length; i++) {
cs[i] = new CountedString("hi");
map.put(cs[i],i);// Autobox int -> Integer
}
System.out.println(map);
for (CountedString c : cs) {
System.out.println("Looking up " + c);
System.out.println(map.get(c));
}
}
}
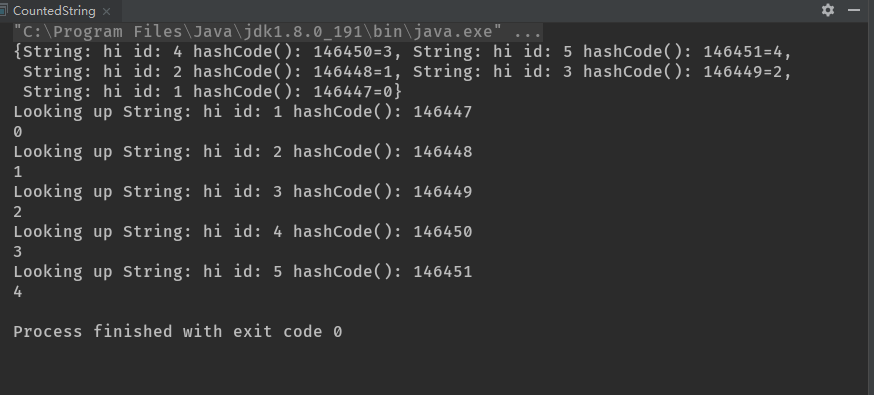
CountedString由一个String和一个id组成,此id代表包含相同String的CountedString对象的编号。所有的String都被存储在static ArrayList中,在构造器中通过迭代遍历此ArrayList完成对id的计算。
hashCode()和equals()都基于CountedString的这两个域来生成结果,如果它们只基于String或者只基于id,不同的对象就可能产生相同的值。
在main()中,使用相同的String创建了多个CountedString对象。这说明,虽然String相同,但是由于id不同,所以使得它们的散列码并不相同。在程序中,HashMap被打印了出来,因此可以看到它内部是如何存储元素的(以无法辨别的次序),然后单独查询每一个键,以此证明查询机制工作正常。
作为第二个示例,请考虑Individual类,它在Thinking in Java——运行时类型信息(RTTI)以及反射:Individual中所定义的typeinfo.pet类库的基类。Individual类在那就用到了,而它的定义则放到了本文,因此你可以正确地理解其实现:
package com.zjwave.thinkinjava.typeinfo.pets;
public class Individual implements Comparable<Individual>{
private static int counter;
private final int id = counter++;
private String name;
public Individual() {
}
public Individual(String name) {
this.name = name;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
if(name != null){
sb.append(name);
}else{
sb.append(this.getClass().getSimpleName());
}
return sb.toString();
}
public int getId() {
return id;
}
@Override
public boolean equals(Object obj) {
return obj instanceof Individual && id == ((Individual) obj).id;
}
@Override
public int hashCode() {
int result = 17;
if(name != null){
result = 37 * result + name.hashCode();
}
result = 37 * result + id;
return super.hashCode();
}
@Override
public int compareTo(Individual o) {
// Compare by class name first
String first = getClass().getSimpleName();
String oFirst = o.getClass().getSimpleName();
int firstCompare = first.compareTo(oFirst);
if(firstCompare != 0){
return firstCompare;
}
if(name != null && o.name != null){
int secondCompare = name.compareTo(o.name);
if(secondCompare != 0){
return secondCompare;
}
}
return o.id < id ? -1 : (o.id == id ? 0 : 1);
}
}
compareTo()方法有一个比较结构,因此它会产生一个排序序列,排序的规则首先按照实际类型排序,然后如果有名字的话,按照name排序,最后按照创建的顺序排序。下面的示例说明了它是如何工作的:
package com.zjwave.thinkinjava.collection;
import com.zjwave.thinkinjava.collection.map.MapOfList;
import com.zjwave.thinkinjava.collection.map.Pet;
import com.zjwave.thinkinjava.typeinfo.pets.Individual;
import java.util.List;
import java.util.Set;
import java.util.TreeSet;
public class IndividualTest {
public static void main(String[] args) {
Set<Individual> pets = new TreeSet<>();
for (List<? extends Pet> lp : MapOfList.petPeople.values()) {
for (Pet p : lp) {
pets.add(p);
}
}
System.out.println(pets);
}
}
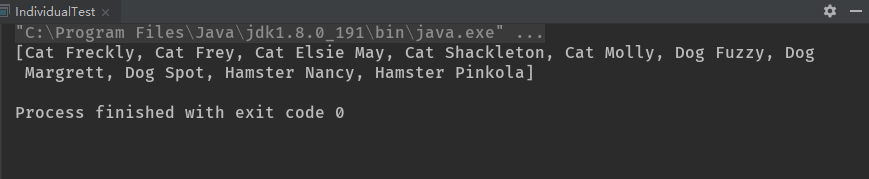
由于所有的宠物都有名字,因此它们首先按照类型排序,然后在同类型中按照名字排序。
为新类编写正确的hashCode()和equals()是很需要技巧的。Apache的Jakarta Commons项目中有许多工具可以帮助你完成此事,该项目可在http://commons.apache.org/proper/commons-lang/下面找到。
10.选择接口的不同实现
现在已经知道了,尽管实际上只有四种容器:Map、List、Set和Queue,但是每种接口都有不止一个实现版本。如果需要使用某种接口的功能,应该如何选择使用哪一个实现呢?
每种不同的实现各自的特征、有点和缺点。例如,从容器分类图中可以看出,Hashtable、Vector和Stack的“特征”是,它们是过去遗留下来的类,目的只是为了支持老的程序(最好不要在新的程序中使用它们)。
在Java类库中不同类型的Queue只在接受和产生数值的方式上有所差异。
容器之间的区别农场归结为由什么在背后“支持”它们。也就是说,所使用的接口是由什么样的数据结构实现的。例如,因为ArrayList和LinkedList都实现了List接口,所以无论选择哪一个,基本的List操作都是相同的。然而,ArrayList底层由数组支持,而LinkedList是由双向链表实现的,其中的每个对象包含数据的同时还包含指向链表中前一个与后一个元素的引用。因此,如果要经常在表中插入或删除元素,LinkedList就比较合适(LinkedList还有建立在AbstractSequentialList基础上的其他功能),否则,应该使用速度更快的ArrayList。
再举个例子,Set可被实现为TreeSet、HashSet或LinkedHashSet。每一种都有不同的行为:HashSet是最常用的,查询速度最快,LinkedHashSet保持元素插入的次序,TreeSet基于TreeMap,生成一个总是处于排序状态的Set。你可以根据所需的行为来选择不同的接口实现。
有时某个特定容器的不同实现会有一些共同的操作,但是这些操作的性能却并不相同。在这种情况下,你可以基于使用某个特定操作的频率,以及你需要的执行速度来在它们中间进行选择。对于类似的情况,一种查看容器实现之间差异的方式是使用性能测试。
10.1 性能测试框架
为了防止代码重复以及为了提供测试的一致性,我将测试过程的基本功能放置到了一个测试框架中国。下面的代码建立了一个基类,从中可以创建一个匿名内部类列表,其中每个匿名内部类都用于每种不同的测试,它们每个都被当做测试过程的一部分而被调用。这种方式使得你可以很方便地添加或移除新的测试种类。
这是模板方法设计模式的另一个示例。尽管你遵循了典型的模板方法模式,覆盖了每个特定测试的Test.test()方法,但是在本例中,其核心代码(不会发生变化)在单独的Tester类中。待测容器类型是泛型参数C:
package com.zjwave.thinkinjava.collection;
public abstract class Test<C> {
String name;
public Test(String name) {
this.name = name;
}
abstract int test(C container,TestParam tp);
}
每个Test对象都存储了该测试的名字。当你调用test()方法时,必须给出待测容器,以及“信使”或“数据传输对象”,他们保存有用于该特定测试的各种参数。这些参数包括size,它表示在容器中的元素数量,以及loops,它用来控制该测试迭代的次数。这些参数在每个测试中都可能会用到,也有可能不会用到。
每个容器都要经历一系列对test()的调用,每个都带有不同的TestParam,因此TestParam还包含静态的array()方法,使得创建TestParam对象数组变得更容易。array()的第一个版本接受的是可变参数列表,其中包括可互换的size和loops的值,而第二个版本接受相同类型的列表,但是它的值都在String中——通过这种方式,它可以用来解析命令行参数:
package com.zjwave.thinkinjava.collection;
public class TestParam {
public final int size;
public final int loops;
public TestParam(int size, int loops) {
this.size = size;
this.loops = loops;
}
// Create an array of TestParam from a varargs sequence:
public static TestParam[] array(int... values){
int size = values.length / 2;
TestParam[] result = new TestParam[size];
int n = 0;
for (int i = 0; i < size; i++) {
result[i] = new TestParam(values[n++],values[n++]);
}
return result;
}
// Convert a String array to a Test array:
public static TestParam[] array(String[] values){
int[] vals = new int[values.length];
for (int i = 0; i < vals.length; i++) {
vals[i] = Integer.decode(values[i]);
}
return array(vals);
}
}
为了使用这个框架,你需要将待测容器以及Test对象列表传递给Tester.run()方法(这些都是重载的泛型便利方法,它们可以减少在使用它们时所必须的类型检查)。Tester.run()方法调用适当的冲在构造器,然后调用timedTest(),它会执行针对该容器的列表中的每一个测试。timedTest()会使用paramList中的每个TestParam对象进行重复测试。因为paramList是从静态的defaultParams数组中初始化出来的,因此你可以通过重新赋值defaultParams,来修改用于所有测试的paramList,或者可以通过传递针对某个测试的定制的paramList,来修改用于该测试的paramList:
package com.zjwave.thinkinjava.collection;
import java.util.List;
public class Tester<C> {
public static int fieldWidth = 8;
public static TestParam[] defaultParams = TestParam.array(10,5000,100,5000,1000,5000,10000,500);
//Override this to modify pre-test initialization
protected C initialize(int size){
return container;
}
protected C container;
private String headline = "";
private List<Test<C>> tests;
private static String stringField(){
return "%" + fieldWidth + "s";
}
private static String numberField(){
return "%" + fieldWidth + "d";
}
private static int sizeWidth = 5;
private static String sizeField = "%" + sizeWidth + "s";
private TestParam[] paramList = defaultParams;
public Tester(C container,List<Test<C>> tests){
this.container = container;
this.tests = tests;
if(container != null){
headline = container.getClass().getSimpleName();
}
}
public Tester(C container,List<Test<C>> tests,TestParam[] paramList){
this(container,tests);
this.paramList = paramList;
}
public void setHeadline(String headline) {
this.headline = headline;
}
// Generic methods for convenience
public static <C> void run(C container,List<Test<C>> tests){
new Tester<>(container,tests).timedTest();
}
public static <C> void run(C container,List<Test<C>> tests,TestParam[] paramList){
new Tester<>(container,tests,paramList).timedTest();
}
private void displayHeader(){
// Calculate width and pad with '-':
int width = fieldWidth * tests.size() + sizeWidth;
int dashLength = width - headline.length() - 1;
StringBuilder head = new StringBuilder(width);
for (int i = 0; i < dashLength / 2; i++) {
head.append("-");
}
head.append(" ");
head.append(headline);
for (int i = 0; i < dashLength / 2; i++) {
head.append("-");
}
System.out.println(head);
// Print column headers:
System.out.format(sizeField,"size");
for (Test<C> test : tests) {
System.out.format(stringField(),test.name);
}
System.out.println();
}
//Run the tests for this container:
public void timedTest(){
displayHeader();
for (TestParam param : paramList) {
System.out.format(sizeField,param.size);
for (Test<C> test : tests) {
C kontainer = initialize(param.size);
long start = System.nanoTime();
// Call the overridden method:
int reps = test.test(kontainer, param);
long duration = System.nanoTime() - start;
long timePerRep = duration / reps;//Nanoseconds
System.out.format(numberField(),timePerRep);
}
}
System.out.println();
}
}
stringField()和numberField()方法会产生用于输出结果的格式化字符串,格式化的标准宽度可以通过修改静态的fieldWidth的值进行调整。displayHeader()方法为每个测试格式化和打印头信息。
如果你需要执行特殊的初始化,那么可以覆盖initialize()方法,这将产生具有恰当尺寸的容器对象——你可以修改现有的容器对象,或者创建新的容器对象。在test()方法中可以看到,其结果被捕获在一个被称为kontainer的局部引用中,这使得你可以将所存储的成员container替换为完全不同的被初始化的容器。
每个Test.test()方法的返回值都必须是该测试执行的操作的数量,这些测试都会计算其所有操作所需的纳秒数。你应该意识到,通常System.nanoTime()所产生的值的粒度都会大于1(这个粒度会随机器和操作系统的不同而不同),因此,在结果中可能会存在某些时间点上的重合。
执行的结果可能会随机器不同而不同,这些测试只是想要比较不同容器的性能。
10.2 对List的选择
下面是对List操作中最本质部分的性能测试。为了进行比较,它还展示了Queue中最重要的操作。该程序创建了两个分离的用于测试每一种容器类的测试列表。在本例中,Queue操作只应用到了LinkedList之上。
package com.zjwave.thinkinjava.collection;
import com.zjwave.thinkinjava.arrays.CountingGenerator;
import com.zjwave.thinkinjava.arrays.Generated;
import java.util.*;
public class ListPerformance {
static Random rand = new Random();
static int reps = 1000;
static List<Test<List<Integer>>> tests = new ArrayList<>();
static List<Test<LinkedList<Integer>>> qTests = new ArrayList<>();
static {
tests.add(new Test<List<Integer>>("add") {
@Override
int test(List<Integer> list, TestParam tp) {
int loops = tp.loops;
int listSize = tp.size;
for (int i = 0; i < loops; i++) {
list.clear();
for (int j = 0; j < listSize; j++) {
list.add(j);
}
}
return loops * listSize;
}
});
tests.add(new Test<List<Integer>>("get") {
@Override
int test(List<Integer> list, TestParam tp) {
int loops = tp.loops * reps;
int listSize = list.size();
for (int i = 0; i < loops; i++) {
list.get(rand.nextInt(listSize));
}
return loops;
}
});
tests.add(new Test<List<Integer>>("set") {
@Override
int test(List<Integer> list, TestParam tp) {
int loops = tp.loops * reps;
int listSize = list.size();
for (int i = 0; i < loops; i++) {
list.set(rand.nextInt(listSize),47);
}
return loops;
}
});
tests.add(new Test<List<Integer>>("iteradd") {
@Override
int test(List<Integer> list, TestParam tp) {
final int LOOPS = 1000000;
int half = list.size() / 2;
ListIterator<Integer> it = list.listIterator(half);
for (int i = 0; i < LOOPS; i++) {
it.add(47);
}
return LOOPS;
}
});
tests.add(new Test<List<Integer>>("insert") {
@Override
int test(List<Integer> list, TestParam tp) {
int loops = tp.loops;
for (int i = 0; i < loops; i++) {
list.add(5,47);//Minimize random-access cost
}
return loops;
}
});
tests.add(new Test<List<Integer>>("remove") {
@Override
int test(List<Integer> list, TestParam tp) {
int loops = tp.loops;
int size = tp.size;
for (int i = 0; i < loops; i++) {
list.clear();
list.addAll(new CountingIntegerList(size));
}
while (list.size() > 5){
list.remove(5);//Minimize random-access cost
}
return loops * size;
}
});
//Tests for queue behavior:
qTests.add(new Test<LinkedList<Integer>>("addFirst") {
@Override
int test(LinkedList<Integer> list, TestParam tp) {
int loops = tp.loops;
int size = tp.size;
for (int i = 0; i < loops; i++) {
list.clear();
for (int j = 0; j < size; j++) {
list.addFirst(47);
}
}
return loops * size;
}
});
qTests.add(new Test<LinkedList<Integer>>("addLast") {
@Override
int test(LinkedList<Integer> list, TestParam tp) {
int loops = tp.loops;
int size = tp.size;
for (int i = 0; i < loops; i++) {
list.clear();
for (int j = 0; j < size; j++) {
list.addLast(47);
}
}
return loops * size;
}
});
qTests.add(new Test<LinkedList<Integer>>("rmFirst") {
@Override
int test(LinkedList<Integer> list, TestParam tp) {
int loops = tp.loops;
int size = tp.size;
for (int i = 0; i < loops; i++) {
list.clear();
list.addAll(new CountingIntegerList(size));
for (int j = 0; j < size; j++) {
list.removeFirst();
}
}
return loops * size;
}
});
qTests.add(new Test<LinkedList<Integer>>("rmLast") {
@Override
int test(LinkedList<Integer> list, TestParam tp) {
int loops = tp.loops;
int size = tp.size;
for (int i = 0; i < loops; i++) {
list.clear();
list.addAll(new CountingIntegerList(size));
for (int j = 0; j < size; j++) {
list.removeLast();
}
}
return loops * size;
}
});
}
static class ListTester extends Tester<List<Integer>>{
public ListTester(List<Integer> container, List<Test<List<Integer>>> tests) {
super(container, tests);
}
// Fill to the appropriate size before each test:
@Override
protected List<Integer> initialize(int size) {
container.clear();
container.addAll(new CountingIntegerList(size));
return container;
}
// Convenience method:
public static void run(List<Integer> list,List<Test<List<Integer>>> tests){
new ListTester(list,tests).timedTest();
}
}
public static void main(String[] args) {
if(args.length > 0){
Tester.defaultParams = TestParam.array(args);
}
// Can only do these two tests on an array:
Tester<List<Integer>> arrayTest = new Tester<List<Integer>>(null,tests.subList(1,3)){
// This will be called before each test,It
// produces a non-resizeable array-backed list:
@Override
protected List<Integer> initialize(int size) {
Integer[] ia = Generated.array(Integer.class, new CountingGenerator.Integer(), size);
return Arrays.asList(ia);
}
};
arrayTest.setHeadline("Array as List");
arrayTest.timedTest();
Tester.defaultParams = TestParam.array(10,5000,100,5000,1000,1000,10000,200);
if(args.length > 0){
Tester.defaultParams = TestParam.array(args);
}
ListTester.run(new ArrayList<>(),tests);
ListTester.run(new LinkedList<>(),tests);
ListTester.run(new Vector<>(),tests);
Tester.fieldWidth = 12;
Tester<LinkedList<Integer>> qTest = new Tester<>(new LinkedList<Integer>(), qTests);
qTest.setHeadline("Queue tests");
qTest.timedTest();
}
}

每个测试都需要仔细地思考,以确保可以产生有意的结果。例如,add测试首先清除List,然后重新填充它到执行的列表尺寸。因此,对clear()的调用也就成了该测试的一部分,并且可能会对执行时间产生影响,尤其是对小型的测试。尽管这里的结果看起来相当合理,但是你可以设想重写测试框架,使得在计时循环之外有一个对准备方法的调用(在本例中将包括clear()调用)。
注意,对于每个测试,你都必须准确地计算将要发生的操作的数量以及从test()中返回的值,因此计时是正确的。
get和set测试都使用了随机数生成器来执行对List的随机访问。在输出中,你可以看到,对于背后有数组支撑的List和ArrayList,无论列表的大小如何,这些访问都很快速和一致,而对于LinkedList,访问时间对于较大的列表将明显增加。很显然,如果你需要执行大量的随机访问,链接列表不会是一种好的选择。
iteradd测试使用迭代器在列表中间插入新的元素。对于ArrayList,当列表变大时,其开销将变得很高昂,但是对于LinkedList,相对来说比较低廉,并且不随列表尺寸而发生变化。这是因为ArrayList在插入时,必须创建空间并将它的所有引用向前移动,这会随ArrayList的尺寸增加而产生高昂的代价。LinkedList只需链接新的元素,而不必修改列表中剩余的元素,因此你可以认为无论列表尺寸如何变化,其代价大致相同。
insert和remove测试都使用了索引位置5作为插入或移除点,而没有选择List两端的元素。LinkedList对List的端点会进行特殊处理——这使得在将LinkedList用作Queue时,湿度可以得到提高。但是,如果你在列表的中间增加或移除元素,其中会包含随机访问的代价,我们已经看到在,这在不同的List实现中变化很大。当执行在位置5的插入和移除时,随机访问的代价应该可以被忽略,但是我们将看不到对LinkedList端点所做的任何特殊优化操作。从输出中可以看出,在LinkedList中的插入和移除代价相当低廉,并且不随列表尺寸发生变化,但是对于ArrayList,插入操作代价特别高昂,并且其代价将随列表尺寸的增加而增加。(注:笔者使用的为JDK8版本,可能结果因版本和机器问题会略有不同)
从Queue测试中,你可以看到LinkedList可以多么快速地从列表的端点插入和移除元素,这正是对Queue行为所做的优化。
通常,你可以只调用Tester.run(),传递容器和tests列表。但是,在这里我们必须覆盖initialize()方法,使得List在每次测试之前,都会被清空并重新填充,否则在不同的测试过程中,对于List尺寸的控制将丧失。ListTester继承自Tester,并使用CountingIntegerList执行这种初始化,run()便捷方法也被覆盖了。
我们还想将数组访问与容器访问进行比较(主要是与ArrayList比较)。在main()的第一个测试中,使用匿名内部类创建了一个特殊的Test对象。initialize()方法被覆盖为在每次被调用时都创建一个新对象(此时会忽略container对象,因此对于这个Tester构造器来说,null就是传递进来的container参数)。这个新对象是使用Generated.array()和Arrays.asList()创建的。在本例中,只有两个测试可以执行,因为你不能在使用背后有数组支撑的List时,插入或移除元素,因此List.subList()方法被用来在tests列表中选取想要执行的测试。
对于随机访问的get()和set()操作,背后有数组支撑的List只比ArrayList稍快一点,但是对于LinkedList,相同的操作会变得异常引入注目的高昂,因为它本来就不是针对随机访问操作而设计的。
应该避免使用Vector,它只存在于支持遗留代码的了库中(在此程序中它能正常工作的唯一原因,只是因为为了向前兼容,它被适配橙了List)。
最佳的做法可能是将ArrayList作为默认首选,只有你需要使用额外的功能,或者当程序的性能因为经常从表中间进行插入和删除而变差的时候,才去选择LinkedList。如果使用的是固定数量的元素,那么既可以选择使用背后有数组支撑的List(就像Arrays.asList()产生的列表),也可以选择真正的数组。
CopyOnWriteArrayList是List的一个特殊实现,专门用于并发编程。将在后续文章中讨论。
10.3 微基准测试的危险
在编写所谓的微基准测试时,你必须要当心,不能做太多的假设,并且要将你的测试窄化,以使得它们尽可能地只在感兴趣的事项上花费精力。你还必须仔细地确保你的测试运行足够长的时间,以产生有意义的数据,并且要考虑到某些Java HosSpot技术只有在程序运行了一段时间之后才会提报问题(这对于短期运行的程序来说也很重要)。
根据计算机和所使用的JVM的不同,所产生的结果也会有所不同,因此你应该自己运行这些测试,以验证得到的结果与本文所示的结果是否相同。你不应该过于关心这些绝对数字,将其看作是一种容器类型与另一种之间的性能比较。
剖析器可以把性能分析工作做得比你好。Java提供了一个剖析器,另外还有很多第三方的自由/开源的和常用的剖析器可用。
有一个与Math.random()相关的示例。它产生的是0到1的值吗?包括还是不包括1?用数学术语表示,就是它是(0,1)、[0,1]、(0,1]还是[0,1)?(方括号表示“包括”,而圆括号表示“不包括”。)
下面的测试程序也许可以提供答案:
package com.zjwave.thinkinjava.collection;
public class RandomBounds {
static void usage(){
System.out.println("Usage:");
System.out.println("\t RandomBounds lower");
System.out.println("\t RandomBounds upper");
System.exit(1);
}
public static void main(String[] args) {
if(args.length != 1){
usage();
}
if(args[0].equals("lower")){
while (Math.random() != 0.0){}
System.out.println("Produced 0.0!");
}else if(args[0].equals("upper")){
while (Math.random() != 1.0){}
System.out.println("Produced 1.0!");
}else{
usage();
}
}
}
为了运行这个程序,你需要键入下面两行命令行中的一行:
java RandomBounds lower或
java RandomBounds upper在这两种情况中,你都需要手工终止程序,因此看起来好像Math.random()永远都不会产生0.0或1.0。但是这正是这类试验产生误导之所在。如果你选取0到1之间大约262个不同的双精度小数,那么通过试验产生其中任何一个值的可能性也许都会超过计算机,甚至试验员本身的生命周期。已证明0.0是包含在Math.random()的输出中的,按照数学术语,即其范围[0,1)。因此,你必须仔细分析你的试验,并理解它们的局限性。
10.4 对Set的选择
可以根据需要选择TreeSet、HashSet或者LinkedHashSet。下面的测试说明了它们的性能表现,据此可在各种实现间做出权衡选择:
package com.zjwave.thinkinjava.collection;
import java.util.*;
public class SetPerformace {
static List<Test<Set<Integer>>> tests = new ArrayList<>();
static {
tests.add(new Test<Set<Integer>>("add") {
@Override
int test(Set<Integer> set, TestParam tp) {
int loops = tp.loops;
int size = tp.size;
for (int i = 0; i < loops; i++) {
set.clear();
for (int j = 0; j < size; j++) {
set.add(j);
}
}
return loops * size;
}
});
tests.add(new Test<Set<Integer>>("contains") {
@Override
int test(Set<Integer> set, TestParam tp) {
int loops = tp.loops;
int span = tp.size * 2;
for (int i = 0; i < loops; i++) {
for (int j = 0; j < span; j++) {
set.contains(j);
}
}
return loops * span;
}
});
tests.add(new Test<Set<Integer>>("iterate") {
@Override
int test(Set<Integer> set, TestParam tp) {
int loops = tp.loops * 10;
for (int i = 0; i < loops; i++) {
Iterator<Integer> it = set.iterator();
while (it.hasNext()){
it.next();
}
}
return loops * set.size();
}
});
}
public static void main(String[] args) {
if(args.length > 0){
Tester.defaultParams = TestParam.array(args);
}
Tester.fieldWidth = 10;
Tester.run(new TreeSet<>(),tests);
Tester.run(new HashSet<>(),tests);
Tester.run(new LinkedHashSet<>(),tests);
}
}
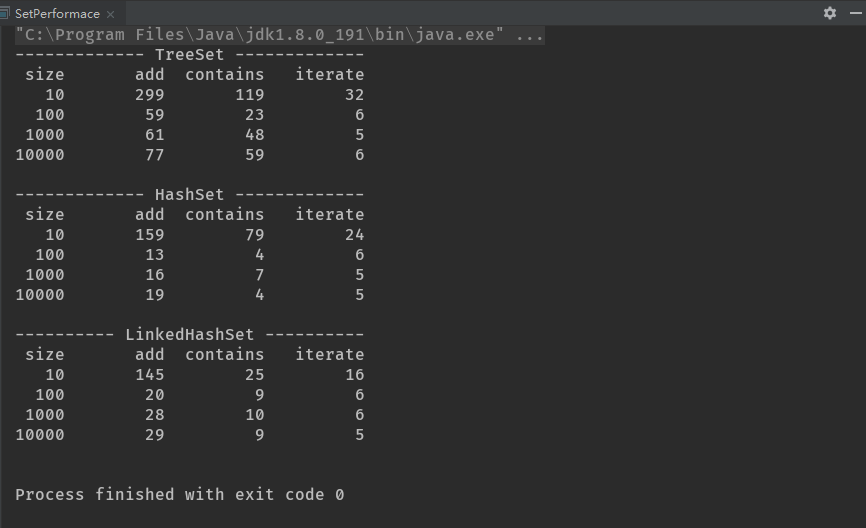
HashSet的性能基本上总是比TreeSet好,特别是在添加和查询元素时,而这两个操作也是最重要的操作。TreeSet存在的唯一原因是它可以维持元素的排序状态,所以,只有当需要一个排好序的Set时,才应该使用TreeSet。因为其内部结构支持排序,并且因为迭代是我们更有可能的操作,所以,用TreeSet迭代通常比用HashSet要快。
注意,对于插入操作,LinkedHashSet比HashSet的代价更高,这是由维护链表所带来额外开销造成的。
10.5 对Map的选择
下面的程序对于Map的不同实现,在性能开销方面给出了指示:
package com.zjwave.thinkinjava.collection;
import java.util.*;
public class MapPerformace {
static List<Test<Map<Integer,Integer>>> tests = new ArrayList<>();
static {
tests.add(new Test<Map<Integer, Integer>>("put") {
@Override
int test(Map<Integer, Integer> map, TestParam tp) {
int loops = tp.loops;
int size = tp.size;
for (int i = 0; i < loops; i++) {
map.clear();
for (int j = 0; j < size; j++) {
map.put(j,j);
}
}
return loops * size;
}
});
tests.add(new Test<Map<Integer, Integer>>("get") {
@Override
int test(Map<Integer, Integer> map, TestParam tp) {
int loops = tp.loops;
int span = tp.size * 2;
for (int i = 0; i < loops; i++) {
for (int j = 0; j < span; j++) {
map.get(j);
}
}
return loops * span;
}
});
tests.add(new Test<Map<Integer, Integer>>("iterate") {
@Override
int test(Map<Integer, Integer> map, TestParam tp) {
int loops = tp.loops * 10;
for (int i = 0; i < loops; i++) {
Iterator<Map.Entry<Integer, Integer>> it = map.entrySet().iterator();
while (it.hasNext()){
it.next();
}
}
return loops * map.size();
}
});
}
public static void main(String[] args) {
if(args.length > 0){
Tester.defaultParams = TestParam.array(args);
}
Tester.run(new TreeMap<>(),tests);
Tester.run(new HashMap<>(),tests);
Tester.run(new LinkedHashMap<>(),tests);
Tester.run(new IdentityHashMap<>(),tests);
Tester.run(new WeakHashMap<>(),tests);
Tester.run(new Hashtable<>(),tests);
}
}

除了IdentityHashMap,所有的Map实现的插入操作都会随着Map尺寸的变大而变慢。但是,查找的代价通常要比插入要小得多,这是个好消息,因为我们执行查找元素的操作要比执行插入元素的操作多得多。
Hashtable的性能大体上与HashMap相当。因为HashMap是用来替代Hashtable的,因此它们使用了相同的底层存储和查找机制。
TreeMap通常比HashMap要慢。与使用TreeSet一样,TreeMap是一种创建有序列表的方式。树的行为是:总是保证有序,并且不必进行特殊的排序。一旦你填充了一个TreeMap,就可以调用keySet()方法来获取键的Set视图,然后调用toArray()来产生由这些件构成的数组。之后,你可以使用静态方法Arrays.binarySearch()在排序数组中快速查找对象。当然,这只有在HashMap的行为不可接受的情况下才有意义,因为HashMap本身就被设计为可以快速查找键。你还可以很方便地通过单个的对象创建操作,或者是调用putAll(),从TreeMap中创建HashMap。最后,当使用Map时,你的第一选择应该是HashMap,只有在你要求Map始终保持有序时,才需要使用TreeMap。
LinkedHashMap在插入时比HashMap慢一点,因为它维护散列数据结构的同时还要维护链表(以保持插入顺序)。正式由于这个列表,使得其迭代速度更快。
IdentityHashMap则具有完全不同的性能,因为它使用==而不是equals()来比较元素。WeakHashMap将在本文稍后介绍。
HashMap的性能因子
我们可以通过手工调整HashMap来提高其性能,从而满足我们特定应用的需求。为了在调整HashMap时让你理解性能问题,某些术语是必须了解的:
- 容量:表中的桶位数
- 初始容量:表在创建时所拥有的桶位数。HashMap和HashSet都具有允许你指定初始容量的构造器。
- 尺寸:表中当前存储的项数。
- 负载因子:尺寸/容量。空表的负载因子是0,而半满表的负载因子是0.5,以此类推。负载轻的表产生冲突的可能性小,因此对于插入和查找都是最理想的(但是会减慢使用迭代器进行遍历的过程)。HashMap和HashSet都具有允许你指定负载因子的构造器,表示当负载情况达到该负载因子的水平时,容器将自动增加其容量(桶位数),实现方式是使容量大致加倍,并重新将现有对象分布到新的桶位中(这被称为再散列)。
HashMap使用的默认负载因子是0.75(只有当表达到四分之三满时,才进行再散列),这个因子在时间和空间代价之间达到平衡。更高的负载因子可以降低表所需的空间,但是会增加查找代价,这很重要,因为查找是我们在大多数时间里所做的操作(包括get()和put())。
如果你知道将要在HashMap中存储多少项,那么创建一个具有恰当大小的初始容量将可以避免自动再散列的开销。
11.实用方法
Java中有大量用于容器的卓越的实用方法,它们被表示为java.util.Collections类内部的静态方法。你已经看到过其中的一部分,例如addAll()、reverseOrder()和binarySearch()。下面是另外一部分(synchronized和unmodifiable的实用方法将在后续介绍)。在这张表中,在相关的情况中使用了泛型:


注意,min()和max()只能作用于Collection对象,而不能作用于List,所以你无需担心Collection是否应该被排序(如前所述,只有在执行binarySearch()之前,才确实需要对List或数组进行排序)。
package com.zjwave.thinkinjava.collection;
import java.util.*;
public class Utilities {
static List<String> list = Arrays.asList("one Two three Four five six one".split(" "));
public static void main(String[] args) {
System.out.println(list);
System.out.println(" 'list' disjoint (Four)?: " + Collections.disjoint(list, Collections.singletonList("Four")));
System.out.println("max: " + Collections.max(list));
System.out.println("min: " + Collections.min(list));
System.out.println("max w/ comparator: " + Collections.max(list, String.CASE_INSENSITIVE_ORDER));
System.out.println("min w/ comparator: " + Collections.min(list, String.CASE_INSENSITIVE_ORDER));
List<String> sublist = Arrays.asList("Four five six".split(" "));
System.out.println("indexOfSubList: " + Collections.indexOfSubList(list, sublist));
System.out.println("lastIndexOfSubList: " + Collections.lastIndexOfSubList(list, sublist));
Collections.replaceAll(list, "one", "Yo");
System.out.println("replaceAll: " + list);
Collections.reverse(list);
System.out.println("reverse: " + list);
Collections.rotate(list,3);
System.out.println("rotate: " + list);
List<String> source = Arrays.asList("in the matrix".split(" "));
Collections.copy(list,source);
System.out.println("copy: " + list);
Collections.swap(list,0,list.size() - 1);
System.out.println("swap: " + list);
Collections.shuffle(list,new Random(47));
System.out.println("shuffle: " + list);
Collections.fill(list,"pop");
System.out.println("fill: " + list);
System.out.println("frequency of 'pop': " + Collections.frequency(list,"pop"));
List<String> dups = Collections.nCopies(3, "snap");
System.out.println("dups: " + dups);
System.out.println("'list' disjoint 'dups'?: " + Collections.disjoint(list,dups));
// Getting an old-style Enumeration:
Enumeration<String> e = Collections.enumeration(dups);
Vector<String> v = new Vector<>();
while (e.hasMoreElements()){
v.addElement(e.nextElement());
}
// Converting an old-style Vector
// to a List via an Enumeration:
ArrayList<String> arrayList = Collections.list(v.elements());
System.out.println("arrayList: " + arrayList);
}
}

该程序的输出可看作是对每个实用方法的行为的解释,请注意由于大小写的缘故而造成的实用String.CASE_INSENSITIVE_ORDER Comparator时min()和max()的拆。
11.1 List的排序和查询
List排序与查询所使用的的方法与对象数组所实用的相应方法有相同的名字与语法,只是用Colletions的static方法代替Arrays的方法而已。下面是一个例子,用到了Utilities.java中的list数据:
package com.zjwave.thinkinjava.collection;
import java.util.*;
public class ListSortSearch {
public static void main(String[] args) {
List<String> list = new ArrayList<>(Utilities.list);
list.addAll(Utilities.list);
System.out.println(list);
Collections.shuffle(list,new Random(47));
System.out.println("Shuffled: " + list);
// Use a ListIterator to trim off the last elements
ListIterator<String> it = list.listIterator(10);
while (it.hasNext()){
it.next();
it.remove();
}
System.out.println("Trimmed: " + list);
Collections.sort(list);
System.out.println("Sorted: " + list );
String key = list.get(7);
int index = Collections.binarySearch(list, key);
System.out.println("Location of " + key + " is " + index + ", list.get(" + index + ") = " + list.get(index));
Collections.sort(list,String.CASE_INSENSITIVE_ORDER);
System.out.println("Case-insensitive sorted: " + list);
key = list.get(7);
index = Collections.binarySearch(list,key, String.CASE_INSENSITIVE_ORDER);
System.out.println("Location of " + key + " is " + index + ", list.get(" + index + ") = " + list.get(index));
}
}
与使用数组进行查找和排序一样,如果使用Comparator进行排序,那么binarySearch()必须使用相同的Comparator。
此程序还演示了Collections的shuffle()方法,它用来打乱List的顺序。ListIterator是在被打乱的列表中的某个特定位置创建的,并用来移除从该位置到列表尾部的所有元素。
11.2 设定Collection或Map为不可修改
创建一个只读的Collection或Map,又是可以带来某些方便。Collections类可以帮助达成此目的,它有一个方法,参数为原本的容器,返回值是容器的只读版本。此方法有大量变种,对应于Collection(如果你不能把Collection视为更具体的类型)、List、Set和Map。下例将说明如何正确生成各种只读容器:
package com.zjwave.thinkinjava.collection;
import java.util.*;
public class ReadOnly {
static Collection<String> data = new ArrayList<>(Countries.names(6));
public static void main(String[] args) {
Collection<String> c = Collections.unmodifiableCollection(new ArrayList<>(data));
System.out.println(c);//Reading is OK
//! c.add("one"); // Can't change it
List<String> a = Collections.unmodifiableList(new ArrayList<>(data));
ListIterator<String> lit = a.listIterator();
System.out.println(lit.next());// Reading is OK
//! lit.add("one");// Cant' change it
Set<String> s = Collections.unmodifiableSet(new HashSet<>(data));
System.out.println(s); //Reading is OK
//! s.add("one");// Can't change it
// For a SortedSet:
SortedSet<String> ss = Collections.unmodifiableSortedSet(new TreeSet<>(data));
Map<String, String> m = Collections.unmodifiableMap(new HashMap<>(Countries.capitals(6)));
System.out.println(m);//Reading is OK
//! m.put("Ralph","Howdy!"); // Can't change it
// For a SortedMap:
SortedMap<String, String> sm = Collections.unmodifiableSortedMap(new TreeMap<>(Countries.capitals(6)));
}
}
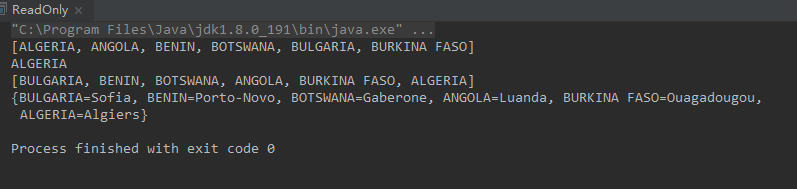
对特定类型的“不可修改的”方法的调用并不会产生编译时的检查,但是转换完成后,任何会改变容器内容的操作都会引起UnsupportedOperationException异常。
无论哪一种情况,在将容器设为只读之前,必须填入有意义的数据。装载数据后,就应该使用“不可修改的”方法返回的引用去替换掉原本的引用。这样,就不用担心无意中修改了只读的内容。另一方面,此方法允许你保留一份可修改的容器,作为类的private成员,然后通过某个方法调用返回该容器的“只读”的引用。这样一来,就只有你可以修改容器的内容,而别人只能读取。
11.3 Collection或Map的同步控制
关键字synchronized是多线程议题中的重要部分,将在后续讨论这种较为复杂的主题。这里,我只提醒读者注意,Collections类有办法能够自动同步整个容器。其语法与“不可修改的”方法相似:
package com.zjwave.thinkinjava.collection;
import java.util.*;
public class Synchronization {
public static void main(String[] args) {
Collection<String> c = Collections.synchronizedCollection(new ArrayList<>());
List<String> list = Collections.synchronizedList(new ArrayList<>());
Set<String> s = Collections.synchronizedSet(new HashSet<>());
Set<String> ss = Collections.synchronizedSortedSet(new TreeSet<>());
Map<String, String> m = Collections.synchronizedMap(new HashMap<>());
Map<String, String> sm = Collections.synchronizedSortedMap(new TreeMap<>());
}
}
最好是如上所示,直接将新生成的容器传递给了适当的“同步”方法,这样做就不会有任何机会暴露出不同步的版本。
快速报错
Java容器有一种保护机制,能够防止多个进程同时修改同一个容器的内容。如果你在迭代遍历某个容器的过程中,另一个进程介入其中,并且插入、删除或修改此容器内的某个对象,那么就会出现问题:也许迭代过程已经处理过容器中的该元素了,也许还没处理,也许在调用size()之后容器的尺寸收缩了——还有许多灾难情景。Java容器类库采用快速报错(fail-fast)机制。他会探查容器上的任何除了你的进程所进行的操作以外的所有变化,一旦它发现其他进程修改了容器,就会立刻抛出ConcurrentModificationException异常。这就是“快速报错”的意思——即,不是使用复杂的算法在事后来检查问题。
很容易就可以看出“快速报错”机制的工作原理:只需创建一个迭代器,然后向迭代器所指向的Collection添加点什么,就像这样:
package com.zjwave.thinkinjava.collection;
import java.util.ArrayList;
import java.util.Collection;
import java.util.ConcurrentModificationException;
import java.util.Iterator;
public class FailFast {
public static void main(String[] args) {
Collection<String> c = new ArrayList<>();
Iterator<String> it = c.iterator();
c.add("An object");
try {
String s = it.next();
}catch (ConcurrentModificationException e){
System.out.println(e);
}
}
}
程序运行时发生了异常,因为在容器取得迭代器之后,又有东西被放入到了该容器中。当程序的不同部分修改同一个容器时,就可能导致容器的状态不一致,所以,此异常提醒你,应该修改代码。在此例中,应该在添加完所有的元素之后,再获取迭代器。
ConcurrentHashMap、CopyOnWriteArrayList和CopyOnWriteArraySet都使用了可以避免ConcurrentModificationException的技术。
12.持有引用
java.lang.ref类库包含了一组类,这些类为垃圾回收提供了更大的灵活性。当存在可能会耗尽内存的大对象的时候,这些类显得特别有用。有三个继承自抽象类Reference的类:SoftReference、WeakReference和PhantomReference。当垃圾回收器正在考察对象只能通过某个Reference对象才“可获得”时,上述这些不同的派生类为垃圾回收器提供了不同级别的间接性指示。
对象是可获得的(reachable),是指此对象可在程序中的某处找到。这意味着你在栈中有一个普通的引用,而它正指向此对象,也可能是你的引用指向某个对象,而那个对象含有另一个引用指向正在讨论的对象,也可能有更多的中间链接。如果一个对象是“可获得的”,垃圾回收器就不能释放它,因为它仍然为你的程序所用。如果一个对象不是“可获得的”,那么你的程序将无法使用到它,所以将其回收是安全的。
如果想继续持有某个对象的引用,希望以后还能够访问到该对象,但是也希望能够允许垃圾回收器释放它,这时就应该使用Reference对象。这样,你可以继续使用该对象,而在内存消耗殆尽的时候又允许释放该对象。
以Reference对象作为你和普通引用之间的媒介(代理),另外,一定不能有普通的引用指向那个对象,这样就能达到上述目的。(普通的引用指没有经Reference对象包装过的引用。)如果垃圾回收器发现某个对象通过普通引用是可获得的,该对象就不会被释放。
SoftReference、WeakReference和PhantomReference由强到弱排列,对应不同级别的“可获得性”。
- SoftReference用以实现内存敏感的高速缓存
- WeakReference是为实现“规范映射”(canonicalizing mappings)而设计的,它不妨碍垃圾回收器回收映射的“键”(或“值”)。“规范映射”中对象的实例可以在程序的多处被同时使用,以节省存储空间。
- PhantomReference用以调度回收前的清理工作,它比Java终止机制更灵活。
使用SoftReference和WeakReference时,可以选择是否要将它们放入ReferenceQueue(用作“回收前清理工作”的工具)。而PhantomReference只能依赖于ReferenceQueue。下面是一个简单的示例:
package com.zjwave.thinkinjava.collection;
import java.lang.ref.*;
import java.util.LinkedList;
public class References {
private static ReferenceQueue<VeryBig> rq = new ReferenceQueue<>();
public static void checkQueue(){
Reference<? extends VeryBig> inq = rq.poll();
if(inq != null){
System.out.println("In queue: " + inq.get());
}
}
public static void main(String[] args) {
int size = 10;
// Or, choose size via the command line:
if(args.length > 0){
size = new Integer(args[0]);
}
LinkedList<SoftReference<VeryBig>> sa = new LinkedList<>();
for (int i = 0; i < size; i++) {
sa.add(new SoftReference<>(new VeryBig("Soft " + i),rq));
System.out.println("Just created: " + sa.getLast());
checkQueue();
}
LinkedList<WeakReference<VeryBig>> wa = new LinkedList<>();
for (int i = 0; i < size; i++) {
wa.add(new WeakReference<>(new VeryBig("Weak " + i),rq));
System.out.println("Just created: " + wa.getLast());
checkQueue();
}
SoftReference<VeryBig> s = new SoftReference<>(new VeryBig("Soft"));
WeakReference<VeryBig> w = new WeakReference<>(new VeryBig("Weak"));
System.gc();
LinkedList<PhantomReference<VeryBig>> pa = new LinkedList<>();
for (int i = 0; i < size; i++) {
pa.add(new PhantomReference<>(new VeryBig("Soft " + i),rq));
System.out.println("Just created: " + pa.getLast());
checkQueue();
}
}
}
class VeryBig{
private static final int SIZE = 10000;
private long[] la = new long[SIZE];
private String ident;
public VeryBig(String ident) {
this.ident = ident;
}
@Override
public String toString() {
return ident;
}
@Override
protected void finalize(){
System.out.println("Finalizing " + ident);
}
}

运行此程序可以看到,尽管还要通过Reference对象访问那些对象(使用get()取得实际的对象引用),但对象还是被垃圾回收器回收了。还可以看到ReferenceQueue总是生成一个包含null对象的Reference。要利用此机制,可以继承特定的Reference类,然后为这个新类添加一些更有用的方法。
12.1 WeakHashMap
容器类中有一种特殊的Map,即WeakHashMap,它被用来保存WeakReference。它使得规范映射更易于使用。在这种映射中,每个值只保存一份实例以节省存储空间。当程序需要那个“值”的时候,边在映射中查询现有的对象,然后使用它(而不是重新再创建)。映射可将值作为其初始化中的一部分,不过通常是在需要的时候才生成“值”。
这是一种节约存储空间的技术,因为WeakHashMap允许垃圾回收器自动清理键和值,所以它显得十分便利。对于向WeakHashMap添加键和值的操作,则没有什么特殊要求。映射会自动使用WeakReference包装它们。允许清理元素的触发条件是,不再需要此键了,如下所示;
package com.zjwave.thinkinjava.collection;
import java.util.WeakHashMap;
public class CanonicalMapping {
public static void main(String[] args) throws Exception{
int size = 1000;
// Or, choose size via the command line:
if(args.length > 0){
size = new Integer(args[0]);
}
Key[] keys = new Key[size];
WeakHashMap<Key, Value> map = new WeakHashMap<>();
for (int i = 0; i < size; i++) {
Key k = new Key(Integer.toString(i));
Value v = new Value(Integer.toString(i));
if(i % 3 == 0){
keys[i] = k; // Save as "real" references
}
map.put(k,v);
}
System.gc();
Thread.sleep(10);
}
}
class Element{
private String ident;
public Element(String ident) {
this.ident = ident;
}
@Override
public String toString() {
return ident;
}
@Override
public int hashCode() {
return ident.hashCode();
}
@Override
public boolean equals(Object obj) {
return obj instanceof Element && ident.equals(((Element) obj).ident);
}
@Override
protected void finalize(){
System.out.println("Finalizing " + getClass().getSimpleName() + " " + ident);
}
}
class Key extends Element{
public Key(String ident) {
super(ident);
}
}
class Value extends Element{
public Value(String ident) {
super(ident);
}
}

可能你的机器运行过快,导致程序在控制台没有打印任何输出就结束了,因此我这里使用了:
Thread.sleep(10);表示使当前线程休眠10毫秒,保证控制台上可以出现输出。
Key类必须有hashCode()和equals(),因为散列数据结构中,它被用作键。有关hashCode()的主题在本文前面部分已经描述过了。
运行此程序,会看到垃圾回收器每隔三个键就跳过一个,因为指向那个键的不同引用被存入了keys数组,所以那些对象不能被垃圾回收器回收。
13. Java 1.0/1.1的容器
很不幸,许多老的代码是使用Java 1.0/1.1的容器写成的,甚至有些新的程序也使用了这些类。因此,虽然在写新的程序时,绝不应该使用旧的容器,但你仍然应该了解它们。不过旧容器功能有限,所以对它们也没太多可说的。毕竟它们都故事了,所以我也不想强调某些设计有多糟糕。
13.1 Vector和Enumeration
在Java 1.0/1.1中,Vector是唯一可以自我扩展的序列,所以它被大量使用。它的缺点多到这里都难以描述。基本上,可将其看作ArrayList,但是具有又长又难记的方法名。在订正过的Java容器类类库中,Vector被改造过,可将其归类为Collection和List。这样做有点不妥当,可能会让人误会Vector变得好用了,实际上这样做只是为了支持Java 2之前的代码。
Java 1.0/1.1版的迭代器发明了一个新名字——枚举,取代了为人熟知的术语(迭代器)。此Enumeration接口比Iterator小,只有两个名字很长的方法:
- boolean hasMoreElements(),如果此枚举包含更多元素,该方法就反悔true
- Object nextElement(),该方法返回此枚举的下一个元素(如果还有的话),否则抛出异常
Enumeration只是接口而不是实现,所以有时新的类库仍然使用了旧的Enumeration,但通常不会造成问题。虽然在你的代码中应该尽量使用Iterator,但也得有所准备,类库可能会返回给你一个Enumeration。
此外,还可以通过使用Collections.enumeration()方法来从Collection生成一个Enumeration,见下面的例子:
package com.zjwave.thinkinjava.collection;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Enumeration;
import java.util.Vector;
public class Enumerations {
public static void main(String[] args) {
Vector<String> v = new Vector<>(Countries.names(10));
Enumeration<String> e = v.elements();
while (e.hasMoreElements()){
System.out.print(e.nextElement() + ", ");
}
e = Collections.enumeration(new ArrayList<>());
}
}

可以调用elements()生成Enumeration,然后使用它来进行前序遍历。最后一行代码创建了一个ArrayList,并且使用enumeration()将ArrayList的Iterator转换成了Enumeration。这样,即使有需要Enumeration的旧代码,你仍然可以使用新容器。
13.2 Hashtable
正如在前面性能比较中所看到的,基本的Hashtable与HashMap很相似,甚至方法名也相似,所以,在新的程序中,没有理由再使用Hashtable而不用HashMap。
13.3 Stack
前面在使用LinkedList时,已经介绍过“栈”的概念。Java 1.0/1.1的Stack很奇怪,竟然不是用Vector来构件Stack,而是继承Vector。所以它拥有Vector所有的特点和行为,再加上一些额外的Stack行为。很难了解设计者是否意识到这样做特别有用处,或者只是一个幼稚的设计。唯一清楚的是,在匆忙发布之前它没有经过仔细审查,因此这个糟糕的设计仍然挂在这里(但是你永远都不应该使用它)。
这里是Stack的一个简单示例,将enum中的每个String表示压入Stack。它还展示了你可以如何方便地将LinkedList用作栈:
package com.zjwave.thinkinjava.collection;
import java.time.Month;
import java.util.LinkedList;
import java.util.Stack;
public class Stacks {
public static void main(String[] args) {
Stack<String> stack = new Stack<>();
for (Month m : Month.values()) {
stack.push(m.toString());
}
System.out.println("stack = " + stack);
// Treating a stack as a Vector:
stack.addElement("The last line");
System.out.println("element 5 = " + stack.elementAt(5));
System.out.println("popping elements:");
while (!stack.empty()){
System.out.print(stack.pop() + " ");
}
System.out.println();
// Using a LinkedList as a Stack:
LinkedList<String> lstack = new LinkedList<>();
for (Month m : Month.values()) {
lstack.addFirst(m.toString());
}
System.out.println("lstack = " + lstack);
while (!lstack.isEmpty()){
System.out.print(lstack.removeFirst() + " ");
}
System.out.println();
// Using the Stack class from
// the holding Your Objects Chapter:
com.zjwave.thinkinjava.collection.stack.Stack stack2 = new com.zjwave.thinkinjava.collection.stack.Stack();
for (Month m : Month.values()) {
stack2.push(m.toString());
}
while (!stack2.empty()){
System.out.print(stack2.pop() + " ");
}
}
}

String表示是从Month enum常量中生成的,用push()插入Stack,然后再从栈的顶端弹出来(用pop())。这里要特别强调:可以在Stack对象上执行Vector操作。这不会有任何问题,因为继承的作用使得Stack是一个Vector,因此所有可以对Vector执行的操作,都可以对Stack执行,例如elementAt()。
前面曾经说过,如果需要栈的行为,应该使用LinkedList,或者从LinkedList类中创建的com.zjwave.thinkinjava.collection.stack.Stack类。
13.4 BitSet
如果想要高效率地存储大量“开/关”信息,BitSet是很好的选择。不过它的效率仅是对空间而言,如果需要高效的访问时间,BitSet比本地数组稍慢一点。
此外,BitSet的最小容量是long:64位。如果存储的内部比较小,例如8位,那么BitSet就浪费了一些空间。因此如果空间对你很重要,最好撰写自己的类,或者直接采用数组来存储你的标志信息(只有在创建包含开关信息列表的大量对象,并且促使你作出决定的依据仅仅是性能和其他度量因素时,才属于这种情况。如果你做出这个决定只是因为你认为某些对象太大了,那么你最终会产生不需要的复杂性,并会浪费掉大量的时间)。
普通的容器都会随着元素的加入而扩充其容量,BitSet也是。以下示范了BitSet是如何工作的:
package com.zjwave.thinkinjava.collection;
import java.util.BitSet;
import java.util.Random;
public class Bits {
public static void printBitSet(BitSet b){
System.out.println("bits: " + b);
StringBuilder bbits = new StringBuilder();
for (int i = 0; i < b.size(); i++) {
bbits.append(b.get(i) ? "1" : "0");
}
System.out.println("bit pattern: " + bbits);
}
public static void main(String[] args) {
Random rand = new Random(47);
// Take the LSB of nextInt()
byte bt = (byte) rand.nextInt();
BitSet bb = new BitSet();
for (int i = 7; i >= 0; i--) {
if(((1 << i) & bt) != 0){
bb.set(i);
}else {
bb.clear(i);
}
}
System.out.println("byte value: " + bt);
printBitSet(bb);
short st = (short) rand.nextInt();
BitSet bs = new BitSet();
for (int i = 15; i >= 0; i--) {
if(((1 << i) & st) != 0){
bs.set(i);
}else {
bs.clear(i);
}
}
System.out.println("short value: " + st);
printBitSet(bs);
int it = rand.nextInt();
BitSet bi = new BitSet();
for (int i = 31; i >= 0; i--) {
if(((1 << i) & it) != 0){
bi.set(i);
}else {
bi.clear(i);
}
}
System.out.println("int value: " + it);
printBitSet(bi);
//Test bitsets >= 64 bits:
BitSet b127 = new BitSet();
b127.set(127);
System.out.println("set bit 127 : " + b127);
BitSet b255 = new BitSet(65);
b255.set(255);
System.out.println("set bit 255 : " + b255);
BitSet b1023 = new BitSet(512);
b1023.set(1023);
b1023.set(1024);
System.out.println("set bit 1023: " + b1023);
}
}
随机数发生器被用来生成随机的byte、short和int,每一个都被转换为BitSet中相应的位模式。因为BitSet是64位的,所有任何生成的随机数都不会导致BitSet扩充容量。然后创建了一个更大的BitSet。你可以看到,BitSet在必要时会进行扩充。
如果拥有一个可以命名的固定的标志集合,那么EnumSet与BitSet相比,通常是一种更好的选择,因为EnumSet允许你按照名字而不是数字位的位置进行操作,因此可以减少错误。EnumSet还可以防止你因不注意而添加新的标志位置,这种行为能够引发严重的、难以发现的缺陷。你应该使用BitSet而不是EnumSet的理由只包括:只有在运行时才知道需要多少个标志,对标志命名不合理,需要BitSet中的某种特殊操作(查看BitSet和EnumSet的JDK文档)。
14.总结
可以证明,容器类库对于面向对象语言来说是最重要的类库。大多数编程工作对容器的使用比对其他类库中的构件都要多。某些语言(例如Python)甚至包含内建的基本容器构件(列表、映射表和集)。
正如你在Thinking in Java——集合(容器)基础中所看到的,通过使用容器,无需费力,就可以完成大量非常有趣的操作。但是,在某些时候,你必须更多地了解容器,以便正确地使用使用它们。特别是,你必须对散列操作有足够的了解,从而能够编写自己的hashCode()方法(并且你必须知道何时需要这么做),你还必须对各种不同的容器实现有足够的了解,这样才能够为你的需要进行恰当的选择。本文覆盖了有关容器类库的这些概念,并讨论了其他有用的细节。至此,你应该已经为在每天的编程任务中使用Java容器做好了充足的准备。
容器类库的设计非常艰难(大多数类库设计问题都是如此。)在C++中,用许多不同的类覆盖了容器类的基础。这与C++容器类之前的可用情况(无任何类可用)相比是一种进步,但是它没有很好地被转译到Java中。在另一个极端情况中,我看到过容器类库由单一的类构成,即Container,它同时起到了线性序列和关联数组的作用。Java容器类库在这二者之间达到了一种平衡:具有成熟的容器类库应该具有的完备的功能,但是比C++容器类和其他类似的容器类库易于学习和使用。这样产生的结果在若干方面看起来都有些奇异,与早期Java类库中所作的某些决策不同,这些奇异性不是偶然的,而是基于复杂性的利弊而仔细权衡的产物。
所有源码均可在https://gitee.com/zjwave/thinkinjava中下载
关联文章:
Thinking in Java——Java异常体系(通过异常处理错误)
Thinking in Java——String及相关类库的使用
Thinking in Java——运行时类型信息(RTTI)以及反射
转载请注明原文链接:ZJ-Wave