
注解(也被称为元数据)为我们在代码中添加信息提供了一种形式化的方法,使我们可以在稍后某个时刻非常方便地使用这些数据。
注解在一定程度上是在把元数据与源代码文件结合在一起,而不是保存在外部文档中这一大的趋势下所催生的。同时,注解也是对来自像C#之类的其他语言对Java造成的语言特性压力所作出的一种回应。
注解是众多引入到Java SE5中的重要语言变化之一。它们可以提供用来完整地描述程序所需的信息,而这些信息是无法用Java来表达的。因此,注解使得我们能够以将由编译器来测试和验证的格式,存储有关程序的额外信息。注解可以用来生成描述符文件,甚至或是新的类定义,并且有助于减轻编写“样板”代码的负担。通过使用注解,我们可以将这些元数据保存在Java源代码中,并利用annotation API为自己的注解构造处理工具,同时,注解的有点还包括:更加干净易读的代码以及编译器类型检查等。虽然Java SE5预先定义了一些元数据,但一般来说,主要还是需要程序员自己添加新的注解,并且按自己的方式使用它们。
注解的语法比较简单,除了@符号的使用之外,它基本与Java固有的语法一致。Java SE5内置了三种,定义在java.lang中的注解:
- @Override,表示当前的方法定义将覆盖超类中的方法。如果你不小心拼写错误,或者方法签名对不上被覆盖的方法,编译器就会发出错误提示。
- @Deprecated,如果程序员使用了注解为@Deprecated的元素,那么编译器就会发出警告信息。
- @SuppressWarnings,关闭不当的编译器警告信息。在Java SE5之前的版本中,也可以使用该注解,不过会被忽略不起作用。
Java还另外提供了四种注解,专门负责新注解的创建。稍后我们将学习它们。
每当你创建描述符性质的类或接口时,一旦其中包含了重复性的工作,那就可以考虑使用注解来简化与自动化该过程。
注解是真正的语言级的概念,一旦构造出来,就享有编译器的类型检查保护。注解(annotation)是在实际的源代码级别保存所有的信息,而不是某种注释性的文字(comment),这使得代码更整洁,且便于维护。通过使用扩展的annotation API,或外部的字节码工具类库,程序员拥有对源代码以及字节码强大的检查与操作能力。
1.基本语法
在下面的例子中,使用@Test对testExecute()方法进行注解。该注解本身并不做任何事情,但是编译器要确保在其构造路径上必须有@Test注解的定义。你将在本文中看到,程序员可以创建一个通过反射机制来运行testExecute()方法的工具。
package com.zjwave.thinkinjava.annotations;
public class Testable {
public void execute(){
System.out.println("Executing...");
}
@Test
void testExecute(){
execute();
}
}被注解的方法与其他的方法没有区别。在这个例子中,注解@Test可以与任何修饰符共同作用与方法,例如public、static或void。从语法的角度来看,注解的使用方式几乎与修饰符的使用一模一样。
1.1 定义注解
下面就是前例中用到的注解@Test的定义。可以看到,注解的定义看起来很像接口的定义。事实上,与其他任何Java接口一样,注解也将会编译器成class文件。
package com.zjwave.thinkinjava.annotations;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface Test {}
除了@符号以外,@Test的定义很像一个空的接口。定义注解时,会需要一些元注解(meta-annotation),如@Target和@Retention。@Target用来定义你的注解将应用于什么地方(例如是一个方法或者一个域)。@Retention用来定义该注解在哪一个级别可用,在源代码中(SOURCE)、类文件中(CLASS)或者运行时(RUNTIME)。
在注解中,一般都会包含一些元素以表示某些值。当分析处理注解时,程序或者工具可以利用这些值。注解的元素看起来就像接口的方法,唯一的区别是你可以为其置顶默认值。
没有元素的注解称为标记注解(marker annotation),例如上例中的@Test。
下面是一个简单的注解,我们可以用它来跟踪一个项目中的用例。如果一个方法或一组方法实现了某个用例的需求,那么程序员可以为此方法加上该注解。于是,项目经理通过计算已经实现的用例,就可以很好地掌控项目的进展。而如果要更新或修改系统的业务逻辑,则维护该项目的开发人员也可以很容易地在代码中找到对应的用例。
package com.zjwave.thinkinjava.annotations;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface UseCase {
public int id();
public String description() default "no description";
}
注意,id和description类似方法定义。由于编译器会对id进行类型检查,因此将用例文档的追踪数据库与源代码相关联是可靠的。description元素有一个default值,如果在注解某个方法时没有给出description的值,则该注解的处理器就会使用此元素的默认值。
在下面的类中,有三个方法被注解为用例:
package com.zjwave.thinkinjava.annotations;
import java.util.List;
public class PasswordUtils {
@UseCase(id = 47 , description = "Passwords must contain at least one numeric")
public boolean validatePassword(String password){
return password.matches("\\w*\\d\\w*");
}
@UseCase(id = 48)
public String encryptPassword(String password){
return new StringBuilder(password).reverse().toString();
}
@UseCase(id = 49,description = "New passwords can't equal previously used ones")
public boolean checkForNewPassword(List<String> prevPasswords,String password){
return !prevPasswords.contains(password);
}
}
注解的元素在使用时表现为名-值对的形式,并需要置于@UseCase声明之后的括号内。在encryptPassword()方法的注解中,并没有给出description元素的值,因此,在UseCase的注解处理器分析处理这个类时会使用该元素的默认值。
你应该能够想象得到如何使用这套工具来“勾勒”出想要建造的系统,然后在建造的过程中逐渐实现系统的各项功能。
1.2 元注解
Java目前只内置了三种标准注解(前面介绍过),以及四种元注解。元注解专职负责注解其它的注解:

大多数时候,程序员主要是定义自己的注解,并编写自己的处理器来处理它们。
2.编写注解处理器
如果没有用来读取注解的工具,那注解也不会比注释更有用。使用注解的过程中,很重要的一个部分就是创建与使用注解处理器。Java SE5扩展了反射机制的API,以帮助程序员构造这类工具。同时,它还提供了一个外部工具apt帮助程序员解析带有注解的Java源代码。
下面是一个非常简单的注解处理器,我们将用它来读取PasswordUtils类,并使用反射机制查找@UseCase标记。我们为其提供了一组id值,然后它会列出在PasswordUtils中找到的用例,以及缺失的用例。
package com.zjwave.thinkinjava.annotations;
import java.lang.reflect.Method;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class UseCaseTracker {
public static void trackUseCases(List<Integer> useCases,Class<?> cl){
for (Method m : cl.getDeclaredMethods()) {
UseCase uc = m.getAnnotation(UseCase.class);
if(uc != null){
System.out.println("Found Use Case: " + uc.id() + " " + uc.description());
useCases.remove(new Integer(uc.id()));
}
}
for (Integer i : useCases) {
System.out.println("Warning: Missing use case-" + i);
}
}
public static void main(String[] args) {
List<Integer> useCases = new ArrayList<>();
Collections.addAll(useCases,47,48,49,50);
trackUseCases(useCases,PasswordUtils.class);
}
}
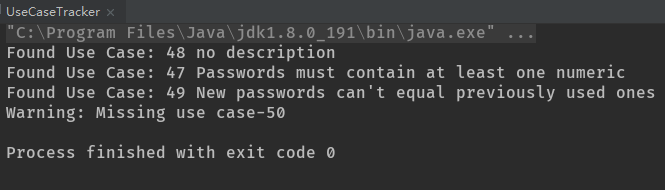
这个程序用到了两个反射方法:getDeclaredMethods()和getAnnotation(),它们都属于AnnotatedElement接口(Class、Method与Field等类都实现了该接口)。getAnnotation()方法返回指定类型的注解对象,在这里就是UseCase。如果被注解的方法上没有该类型的注解,则返回null值。然后我们通过调用id()和description()方法从返回的UseCase对象中提取元素的值。其中,encryptPassword()方法在注解的时候没有指定description的值,因此处理器在处理它对应的注解时,通过description()方法取得的是默认值no description。
2.1 注解元素
标签@UseCase由UseCase.java定义,其中包含int元素id,以及一个String元素description。注解元素可用的类型如下所示:
- 所有基本类型(int,float,boolean等)
- String
- Class
- enum
- Annotation
- 以上类型的数组
如果你使用了其他类型,那编译器就会报错。注意,也不允许使用任何包装类型,不过由于自动打包的存在,这不算是什么限制。注解也可以作为元素的类型,也就是说注解可以嵌套,稍后你会看到,这是一个很有用的技巧。
2.2 默认值限制
编译器对元素的默认值有些过分挑剔。首先,元素不能有不确定的值。也就是说,元素必须要么具有默认值,要么在使用注解时提供元素的值。
其次,对于非基本类型的元素,无论是在源代码中声明时,或是在注解接口中定义默认值时,都不能以null作为其值。这个约束使得处理器很难表现一个元素的存在或缺失的状态,因为在每个注解的声明中,所有的元素都存在,并且都具有相应的值。为了绕开这个约束,我们只能自己定义一些特殊的值,例如空字符串或负数,以此表示某个元素不存在:
package com.zjwave.thinkinjava.annotations;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface SimulatingNull {
int id() default -1;
String description() default "";
}
在定义注解的时候,这算得上是一个习惯用法。
2.3 生成外部文件
有些framework需要一些额外的信息才能与你的源代码协同工作,而这种情况最适合注解表现其价值了。像(EJB3之前)Enterprise JavaBean这样的技术,每一个Bean都需要大量的接口和部署来描述文件,而这些都属于“样板”文件。Web Service、Spring、自定义标签库以及对象/关系映射工具等,一般都需要XML描述文件,而这些描述文件脱离于源代码之外。因此,在定义了Java类之后,程序员还必须得忍受着沉闷,重复地提供某些信息,例如类名和包名等已经在原始的类文件中提供了的信息。每当程序员使用外部的描述文件时,他就拥有了同一个类的两个单独的信息源,这经常导致代码同步问题。同时,它也要求为项目工作的程序员,必须同时知道如何编写Java程序,以及如何编辑描述文件。
假设你希望提供一些基本的对象/关系映射功能,能够自动生成数据库表,用以存储JavaBean对象。你可以选择使用XML描述文件,指明类的名字、每个成员以及数据库映射的相关信息。然而,如果使用注解的话,你可以将所有信息都保存在JavaBean源文件中。为此,我们需要一些新的注解,用以定义与Bean关联的数据库表的名字,以及与Bean属性关联的列的名字和SQL类型。
以下是一个注解的定义,它告诉注解处理器,你需要为我生成一个数据库表:
package com.zjwave.thinkinjava.annotations.database;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface DBTable {
public String name() default "";
}
在@Target注解中指定的每一个ElementType就是一个约束,它告诉编译器,这个自定义的注解只能应用于该类型。程序员可以指定enum ElementType中的某一个值,或者以逗号分隔的形式指定多个值。如果想要将注解应用于所有的ElementType,那么可以省去@Target元注解,不过这并不常见。
注意,@DBTable有一个name()元素,该注解通过这个元素为处理器创建数据库表提供表的名字。
接下来是为修饰JavaBean域准备的注解:
package com.zjwave.thinkinjava.annotations.database;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
public @interface Constraints {
boolean primaryKey() default false;
boolean allowNull() default true;
boolean unique() default false;
}
package com.zjwave.thinkinjava.annotations.database;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
public @interface SQLString {
int value() default 0;
String name() default "";
Constraints constraints() default @Constraints;
}
package com.zjwave.thinkinjava.annotations.database;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
public @interface SQLInteger {
String name() default "";
Constraints constraints() default @Constraints;
}
注解处理器通过@Constraints注解提取出数据库表的元数据。虽然对于数据库所能提供的所有约束而言,@Constraints注解值表示了它的一个很小的子集,不过它所要表达的思想已经很清楚了primaryKey()、allowNull()和unique()元素明智地提供了默认值,从而在大多数情况下,使用该注解的程序员无需输入太多东西。
另外两个@interface定义的是SQL类型。如果希望这个framework更有价值的话,我们就应该为每种SQL类型都定义相应的注解。不过作为示例,两个类型足够了。
这些SQL类型具有name()元素和constraint()元素。后者利用了嵌套注解的功能,将column类型的数据库约束信息嵌入其中。注意constraint()元素的默认值是@Constraint。由于在@Constraint注解类型之后,没有在括号中指明@Constraint中的元素的值,因此,constraint()元素的默认值实际上就是一个所有元素都为默认值的@Constraint注解。如果要令嵌入的@Constraint注解中的unique()元素为true,并以此作为constraint()元素的默认值,则需要如下定义该元素:
package com.zjwave.thinkinjava.annotations.database;
public @interface Uniqueness {
Constraints constraints() default @Constraints(unique = true);
}
下面是一个简单的Bean定义,我们在其中应用了以上这些注解:
package com.zjwave.thinkinjava.annotations.database;
@DBTable(name = "MEMBER")
public class Member {
@SQLString(30)
String firstName;
@SQLString(50)
String lastName;
@SQLInteger
Integer age;
@SQLString(value = 30,constraints = @Constraints(primaryKey = true))
String handle;
static int memberCount;
public String getFirstName() {
return firstName;
}
public String getLastName() {
return lastName;
}
public Integer getAge() {
return age;
}
public String getHandle() {
return handle;
}
@Override
public String toString() {
return handle;
}
}
类的注解@DBTable给定了值MEMBER,它将会用来作为表的名字。Bean的属性firstName和lastName,都被注解为@SQLString类型,并且其元素值分别为30和50。这些注解有两个有趣的地方:
- 它们都使用了嵌入的@Constraint注解的默认值
- 它们都使用了快捷方式。
何谓快捷方式呢,如果程序员的注解中定义了名为value的元素,并且在应用该注解的时候,如果该元素是唯一需要赋值的一个元素,那么此时无需使用名-值对的这种语法,而只需在括号内给出value元素所需的值即可。这可以应用于任何合法类型的元素。当然了,这也限制了程序员必须将此元素命名为value,不过在上面的例子中,这不但使语义更清晰,而且这样的注解语句也更易于理解:
@SQLString(30)处理器将在创建表的时候使用该值设置SQL列的大小。
默认值的语法虽然很灵巧,但它很快就变得复杂起来。以handle域的注解为例,这是一个@SQLString注解,同时,该域将成为表的主键,因此在嵌入的@Constraint注解中,必须对primaryKey元素进行设定。这是事情就变得麻烦了。现在,你不得不使用很长的名-值对形式,重新写出元素名和@interface的名字。与此同时,由于有特殊命名的value元素已经不再是唯一需要复制的元素了,所以你也不能再使用快捷方式为其复制了。如你所见,最终的结果算不上清晰易懂。
变通之道
可以使用多种不同的方式来定义自己的注解,以实现上例的功能。例如,你可以使用一个单一的注解类@TableColumn,它带有一个enum元素,该枚举类定义了STRING、INTEGER以及FLOAT等枚举实例。这就消除了每个SQL类型都需要一个@interface定义的负担,不过也使得额外的信息修饰SQL类型的需求变得不可能,而这些额外的信息,例如长度或精度等,可能是非常有必要的需求。
我们也可以使用String元素来描述实际的SQL类型,比如VARCHAR(30)或INTEGER。这使得程序员可以修饰SQL类型。但是,它同时也将Java类型到SQL类型的映射绑在了一起,这可不是一个好的设计。我们可不希望更换数据库导致代码必须修改并重新编译。如果我们只需告诉注解处理器,我们正在使用的是什么“口味”的SQL,然后由处理器为我们处理SQL类型的细节,那将是一个优雅的设计。
第三种可行的方案是同时使用两个注解类型来注解一个域,@Constraint和相应的SQL类型(例如@SQLInteger)。这种方式可能会是代码有点乱,不过编译器允许程序员对一个目标同时使用多个注解。注意,使用多个注解的时候,同一个注解不能重复使用。
2.4 注解不支持继承
不能使用关键字extends来继承某个@interface。这真是一个遗憾。如果可以定义一个@TableColumn注解(参考前面的建议),同时在其中嵌套一个@SQLType类型的注解,那么这将成为一个优雅的设计。按照这种方式,程序员可以继承@SQLType,从而创建出各种SQL类型,例如@SQLInteger和@SQLString等。如果注解允许继承的话,这将大大减少打字的工作量,并且使语法更整洁。在Java未来的版本中,似乎没有任何关于让注解支持继承的提案,所以,在当前状况下,上例中的解决方案可能已经是最佳方法了。
2.5 实现处理器
下面是一个注解处理器的例子,它将读取一个类文件,检查其上的数据库注解,并生成用来创建数据库的SQL命令:
package com.zjwave.thinkinjava.annotations.database;
import java.lang.annotation.Annotation;
import java.lang.reflect.Field;
import java.util.ArrayList;
import java.util.List;
public class TableCreator {
/**
* Args : com.zjwave.thinkinjava.annotations.database.Member
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
if(args.length < 1){
System.out.println("arguments: annotated classes");
System.exit(0);
}
for (String className : args) {
Class<?> cl = Class.forName(className);
DBTable dbtable = cl.getAnnotation(DBTable.class);
if(dbtable == null){
System.out.println("No DbTable annotations in class " + className);
continue;
}
String tableName = dbtable.name();
// If the name is empty , use the Class name:
if(tableName.length() < 1){
tableName = cl.getName().toUpperCase();
}
List<String> columnDefs = new ArrayList<>();
for (Field field : cl.getDeclaredFields()) {
String columnName = null;
Annotation[] anns = field.getDeclaredAnnotations();
if(anns.length < 1){
continue; // Not a db table column
}
if(anns[0] instanceof SQLInteger){
SQLInteger sInt = (SQLInteger) anns[0];
// Use field name if name not specified
if(sInt.name().length() < 1){
columnName = field.getName().toUpperCase();
}else {
columnName = sInt.name();
}
columnDefs.add(columnName + " INT" + getConstraints(sInt.constraints()));
}else if(anns[0] instanceof SQLString){
SQLString sString = (SQLString) anns[0];
// Use field name if name not specified.
if(sString.name().length() < 1){
columnName = field.getName().toUpperCase();
}else {
columnName = sString.name();
}
columnDefs.add(columnName + " VARCHAR(" + sString.value() +")" + getConstraints(sString.constraints()));
}
}
StringBuilder createCommand = new StringBuilder("CREATE TABLE " + tableName + "(");
for (String columnDef : columnDefs) {
createCommand.append("\n " + columnDef + ",");
}
//Remove trailing comma
String tableCreate = createCommand.substring(0, (createCommand.length() - 1)) + ");";
System.out.println("Table.Creation SQL for " + className + " is :\n " + tableCreate);
}
}
private static String getConstraints(Constraints con){
String constraints = "";
if(!con.allowNull()){
constraints += " NOT NULL";
}
if(con.primaryKey()){
constraints += " PRIMARY KEY";
}
if(con.unique()){
constraints += " UNIQUE";
}
return constraints;
}
}

main()方法会处理命令行传入的每一个类名。使用forName()方法加载每一个类,并使用getAnnotation(DBTable.class)检查该类是否带有@DBTable注解。如果有,就将发现的表名保存下来。然后读取这个类的所有域,并用getDeclaredAnnotations()进行检查。该方法返回一个包含一个域上的所有注解的数组。最后用instanceof操作符来判断这些注解是否是@SQLInteger或@SQLString类型,如果是的话,在对应的处理块汇总将构造出相应column名的字符串片段。注意,由于注解没有继承机制,所以要获得近似多态的行为,使用getDeclaredAnnotations()是唯一的办法。
嵌套中的@Constraint注解被传递给getConstraints()方法,由它负责构造一个包含SQL约束的String对象。
需要注意的是,上面演示的技巧对于真实的对象/关系映射而言,是很幼稚的。例如使用@DBTable类型的注解,程序员以参数的形式给出表的名字,如果程序员想要修改表的名字,这将迫使其必须重新编译Java代码。这可不是我们希望看到的结果。现在已经有了很多可用的framework,可用将对象映射到关系数据库,并且,其中越来越多的framework已经开始利用注解了。
所有源码均可在https://gitee.com/zjwave/thinkinjava中下载
关联文章:
Thinking in Java——Java异常体系(通过异常处理错误)
Thinking in Java——String及相关类库的使用
Thinking in Java——运行时类型信息(RTTI)以及反射
转载请注明原文链接:ZJ-Wave
共有 0 条评论